Learn how you can create an ingest data flow to move data from Kafka to S3 buckets.
This involves opening Apache NiFi in your Flow Management cluster, adding processors and other
data flow objects to your canvas, and connecting your data flow elements.
You can use the PutHDFS or PutS3Object
processors to build your AWS ingest data flows. Regardless of the type of flow you are
building, the first steps in building your data flow are generally the same. Open NiFi, add
your processors to the canvas, and connect the processors to create the flow.
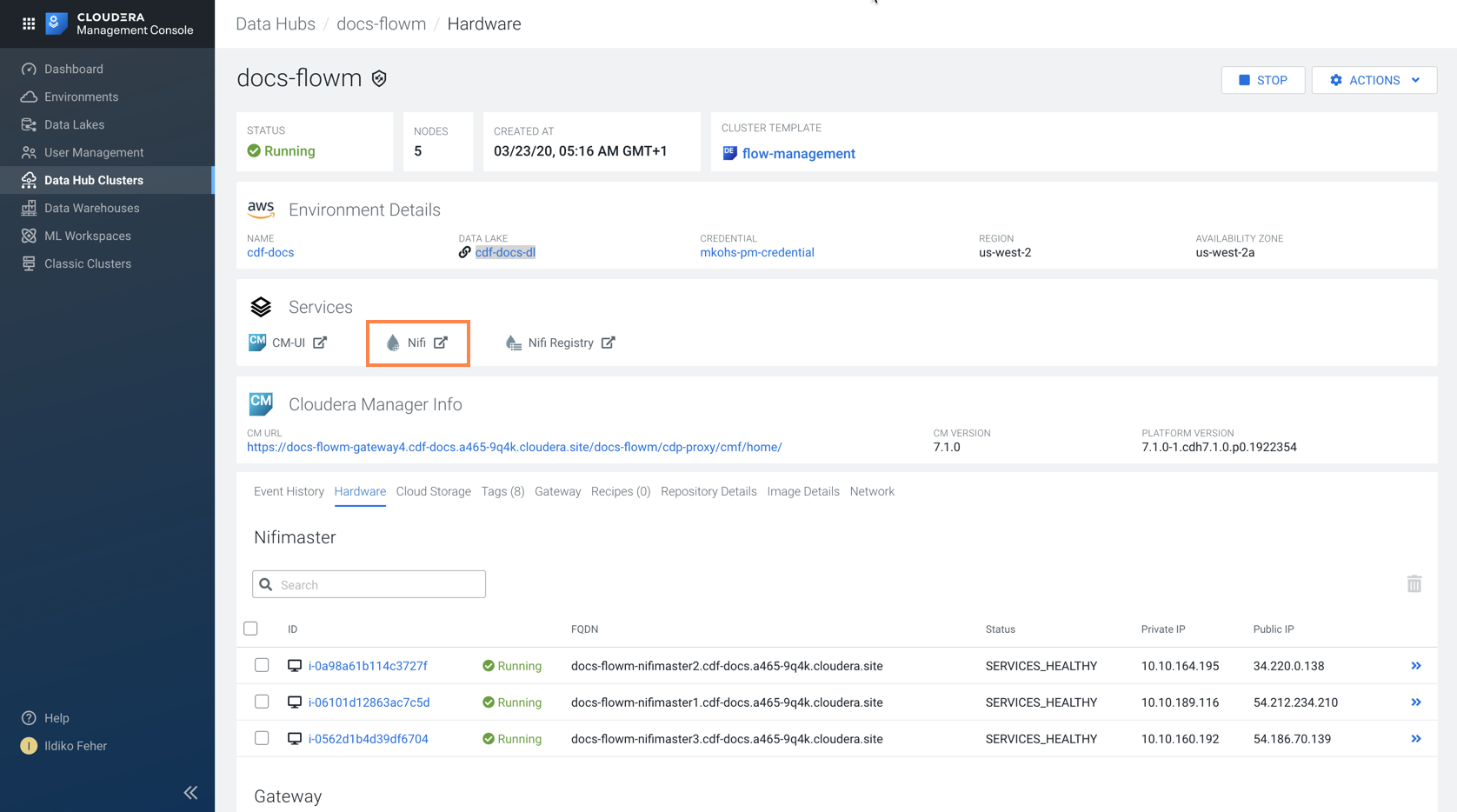
Open NiFi in Data Hub.
To access the NiFi service in your Flow Management Data Hub cluster, navigate to
Management Console service > Data Hub
Clusters.
Click the tile representing the Flow Management Data Hub cluster you want to
work with.
Click Nifi in the Services
section of the cluster overview page to access the NiFi UI.
You will be logged into NiFi automatically with your CDP
credentials.
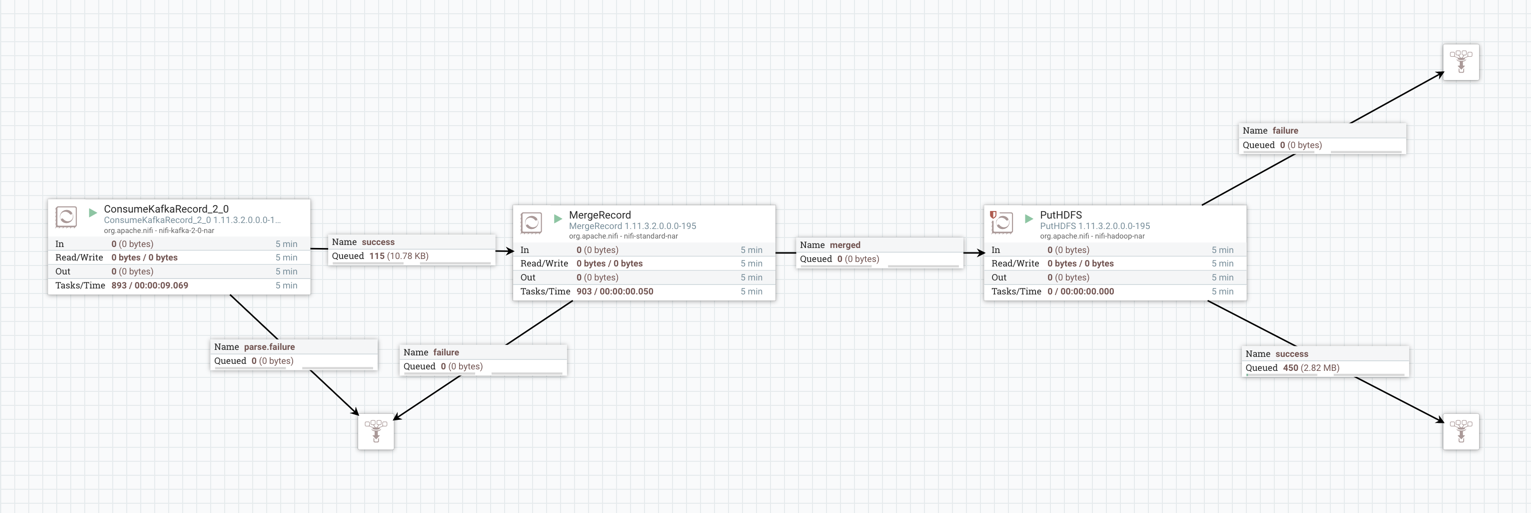
Add the ConsumeKafkaRecord_2_0 processor for data input in your
data flow.
Drag and drop the processor icon into the canvas.
This displays a
dialog that allows you to choose the processor you want to add.
Select the ConsumeKafkaRecord_2_0 processor from the
list.
Click Add or double-click the required processor type
to add it to the canvas.
Add the MergeRecord processor.
When using the ConsumeKafkaRecord_2_0 processor, you are pulling
small-sized records, so it is practical to merge them into larger files before writing
them to S3.
Add a processor for writing data to S3.
You have two
options:
PutHDFS processor: The HDFS client writes to S3 through the S3A
API. This solution leverages centralized CDP security. You can use the usernames and
passwords you set up in CDP for central authentication, and all requests go through
IDBroker.
PutS3Object processor: This is an S3-specific processor that
directly interacts with the Amazon S3 API. It is not integrated into CDP’s
authentication and authorization frameworks. If you use it for data ingestion, the
authorization process is handled in AWS, and you need to provide the AWS access
credentials file / information when configuring the processor. You can do this by:
Providing your access key / secret key pair
Using a Credentials File where you give the path to a file that contains
your AWS access key and secret key
Using the AWSCredentialsProvider Controller Service in your data
flow.
Drag and drop the processor icon into the canvas.
In the dialog
box you can choose which processor you want to add.
Select the processor of your choice from the list.
Click Add or double-click the required processor type
to add it to the canvas.
Connect the processors to create the data flow by clicking the connection icon in
the first processor, and dragging and dropping it on the second processor.
A Create Connection dialog appears with two tabs:
Details and Settings. You can configure
the connection's name, flowfile expiration time period, thresholds for back pressure,
load balance strategy and prioritization.
Connect ConsumeKafkaRecord_2_0 with
MergeRecord.
Add the success flow of the ConsumeKafkaRecord_2_0
processor to the MergeRecord processor.
Click Add to close the dialog box and add the
connection to your data flow.
Connect MergeRecord with your target data processor
(PutHDFS / PutS3Object).
Add the merged flow of the MergeRecord processor
to the target data processor.
Click Add to close the dialog box and add the
connection to your data flow.
Optionally, you can add funnels to your flow.
ConsumeKafkaRecord_2_0: If any of the Kafka messages are
pulled but cannot be parsed, the continents of the message will be written to a
separate flowfile and that flowfile will be transferred to the parse.failure
relationship. You can connect the failure queue coming from the processor to a failure
funnel for parse failures.
MergeRecord: For merge failures, you can connect the
failure queue coming from the processor to the failure funnel you used for
ConsumeKafkaRecord_2_0.
PutHDFS / PutS3Object: You can add
success and failure funnels at the end of the data flow and connect them with your
target data processor. These funnels help you see where flow files are being routed
when your flow is running.
If you want to know more about working with funnels, see the Apache
NiFi User Guide.
This example data flow has been created using the
PutHDFS processor.
If you are using the PutHDFS processor, configure IDBroker mapping
authorization.
If you are using the PutS3Objectprocessor, you do not need IDBroker
mapping, so proceed to configuring controller services for the processors in your data
flow.