Build the data flow
Learn how you can build a data flow using the object store processors to fetch data from one bucket, and after data transformation, ingest the data into another bucket. This involves opening Apache NiFi in your Flow Management cluster, adding processors and other data flow objects to your canvas, and connecting your data flow elements.
Use the ListCDPObjectStore and FetchCDPObjectStore processors to list and fetch data from your source bucket. Then, after transforming the data, use the PutCDPObjectStore to push the transformed data into the target bucket. Use the DeleteCDPObjectStore to delete your data in the source bucket.
Regardless of the type of flow you are building, the first steps in building your data flow are generally the same. Open NiFi, add your processors to the canvas, and connect the processors to create the flow.
-
Open NiFi
in
Data Hub.
-
Click NiFi in the
Services section of the cluster overview page
to access the NiFi UI.
You will be logged into NiFi automatically with your CDP credentials. -
Click NiFi in the
Services section of the cluster overview page
to access the NiFi UI.
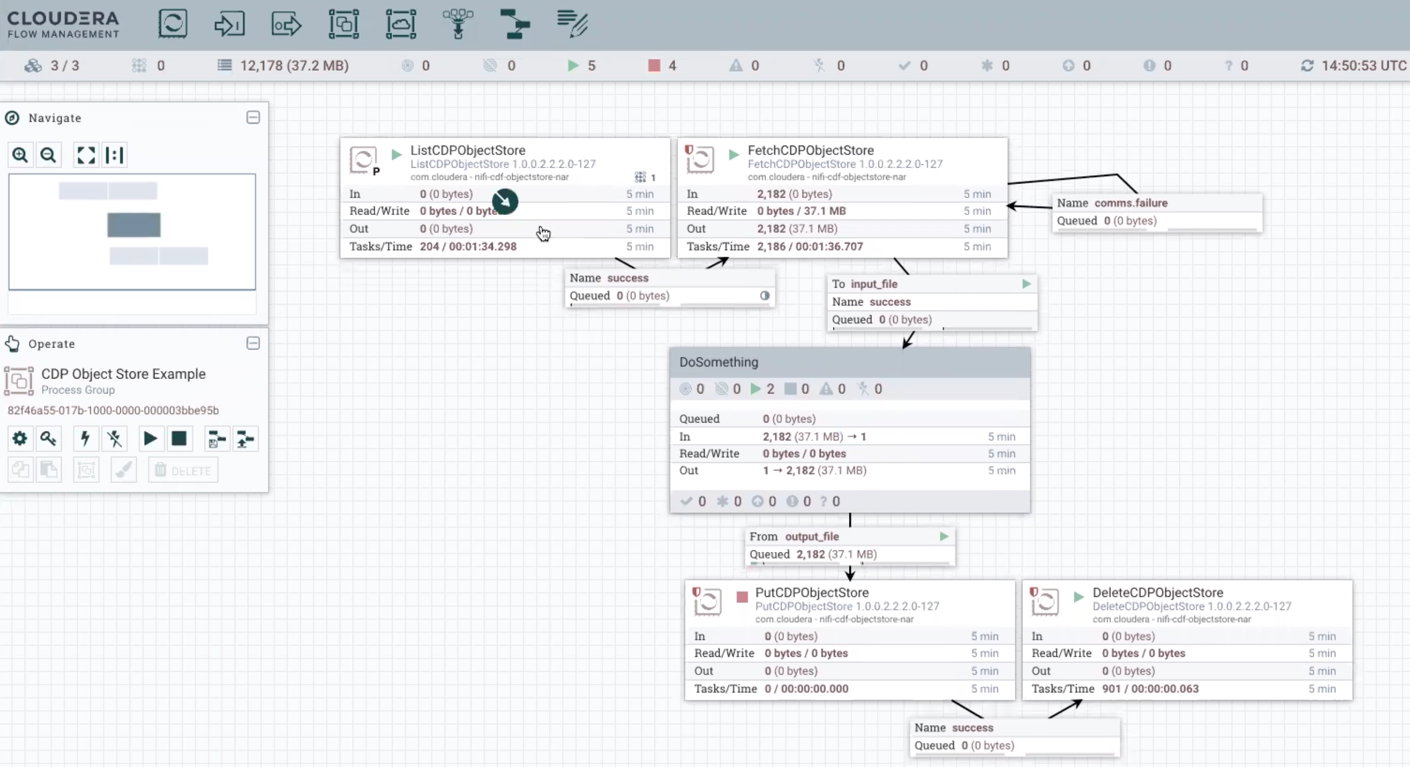
Configure each object store processor in your data flow.