With Cloudera SQL Stream Builder, you can create powerful custom functions in Python to enhance the functionality of SQL.
User functions can be simple translation functions like Celsius to Fahrenheit, more complex business logic, or even looking up data from external sources. User functions are written in Python. When you write them, you can create a library of useful functions.
The following Python versions are supported in Cloudera SQL Stream Builder
:
3.8
3.9
3.10
To use Python UDFs:
Navigate to the Streaming SQL Console.
Navigate to Management Console > Environments, and select the environment where you have created your
cluster.
Select the Streaming Analytics cluster from the list of
Data Hub clusters.
Select Streaming SQL Console from the list of
services.
The Streaming SQL Console opens in a new window.
Open a project from the Projects page of Streaming SQL
Console.
Select an already existing project from the list by clicking the
Open button or Switch button.
Create a new project by clicking the New Project
button.
Import a project by clicking the Import button.
You are redirected to the Explorer view of the project.
Click next to Functions.
Click New Function.
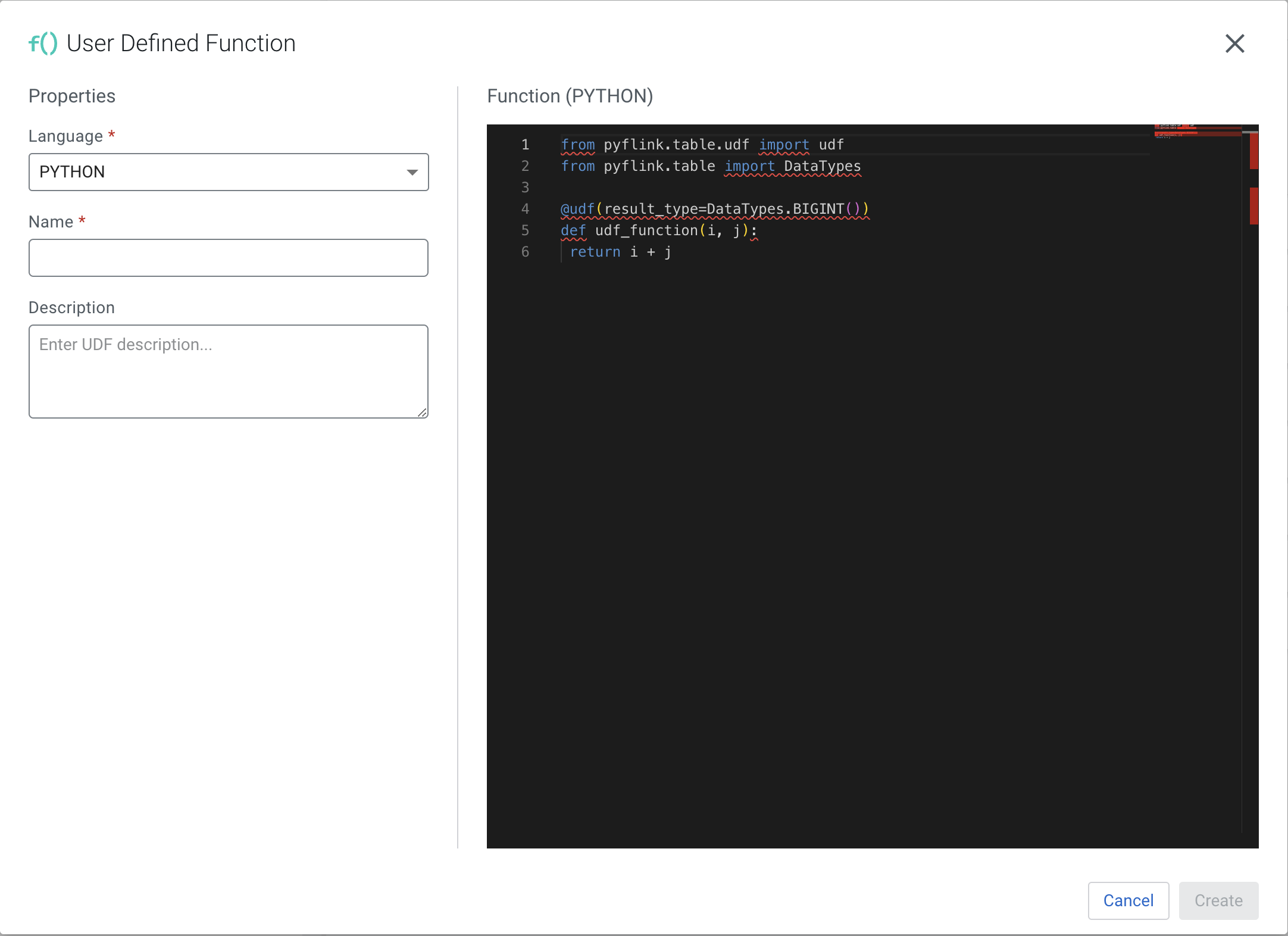
From the dropdown menu select PYTHON.
Add a Name to the UDF.
For example, name the UDF to ADD_FUNCTION.
Add a Description to the UDF. (Optional.)
Paste the Python code to the editor.
For
example, a simple addition:
from pyflink.table.udf import udf
from pyflink.table import DataTypes
@udf(result_type=DataTypes.BIGINT())
def udf_function(i, j):
return i + j
Click Create.
Once created, you can use the new User Defined Function in your SQL statement or as a computed column when creating a table.
For
example:
-- as a SQL statement
SELECT ADD_FUNCTION(myTable.n1, myTable.n2)
-- as a computed column
CREATE TABLE myTable (
`number_a` BIGINT,
`number_b` BIGINT
`sum` AS ADD_FUNCTION(number_a, number_b) -- evaluate expression and supply the result to queries
) WITH (
'connector' = 'kafka'
...
);
When a Flink job starts, Cloudera SQL Stream Builder will upload the Python file to the Artifact Storage, accessible for Flink to execute the UDF when called. The ssb.python.udf.reaper.period.seconds and ssb.python.udf.ttl configuration properties (set in Cloudera Manager) control the behavior of SSB to remove Python files associated with terminated jobs.
 next to Functions.
next to Functions.