Architecture
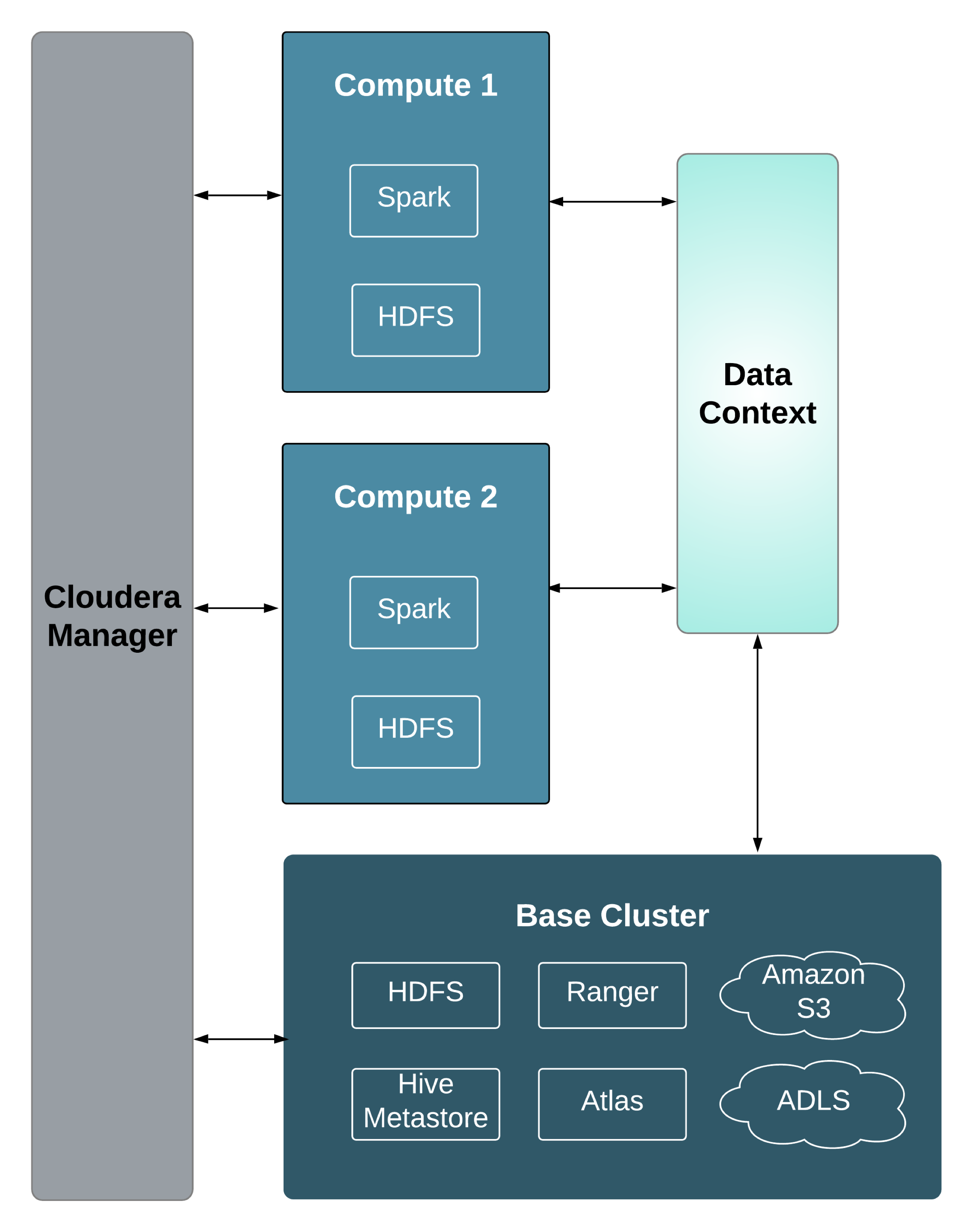
If you are creating Virtual Private Clusters, it is important to understand the architecture of compute clusters and how they related to Data contexts.
A Compute cluster is configured with compute resources such as Spark or Hive Execution. Workloads running on these clusters access data by connecting to a Data Context for the Base cluster. A Data Context is a connector to a Regular cluster that is designated as the Base cluster. The Data context defines the data, metadata and security services deployed in the Base cluster that are required to access the data. Both the Compute cluster and Base cluster are managed by the same instance of Cloudera Manager. A Base cluster can contain any Cloudera Runtime services -- but only HDFS, Hive, Atlas, Ranger, Amazon S3, and Microsoft ADLS can be shared using the data context.
- Hive Execution Service (This service supplies the HiveServer2 role only.)
- Hue
- Kafka
- Spark
- Oozie (only when Hue is available, and is a requirement for Hue)
- YARN
- HDFS
The functionality of a Virtual Private cluster is a subset of the functionality available in Regular clusters, and the versions of Cloudera Runtime that you can use are limited. For more information, see Compatibility Considerations for Virtual Private Clusters.