Configuring Replication of HDFS Data
You must set up your clusters before you configure HDFS data replication job.
-
From Cloudera Manager, select .
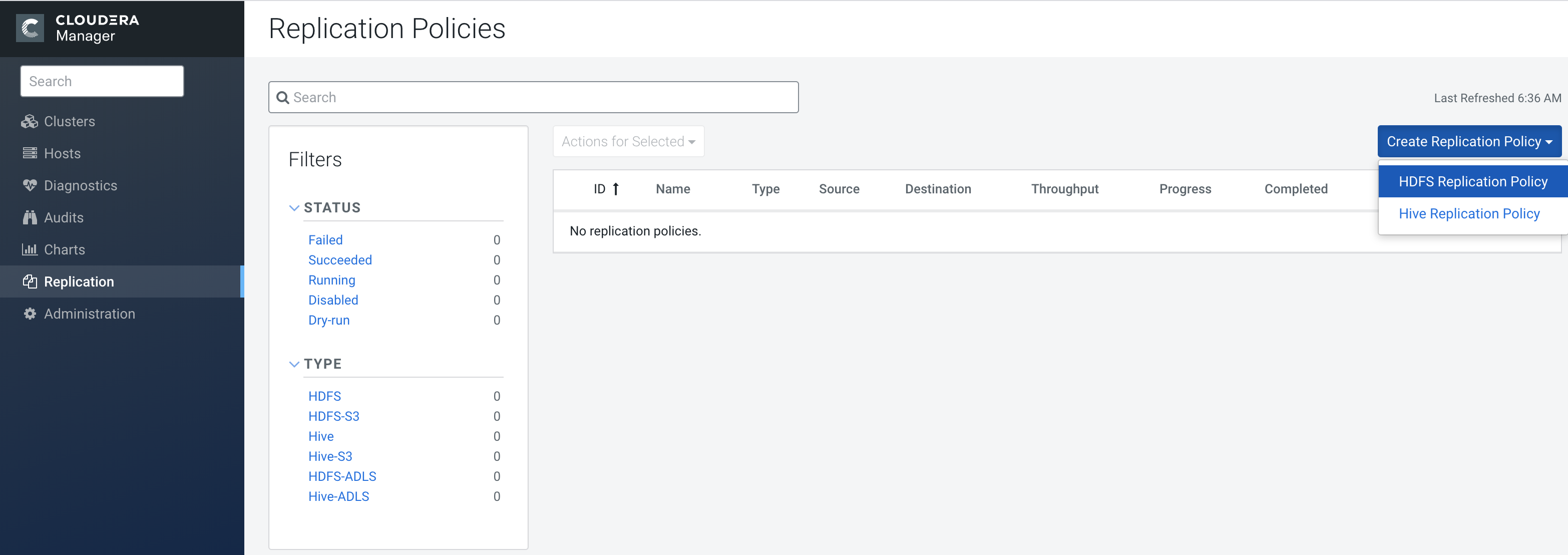
-
Select HDFS Replication Policy.
The Create HDFS Replication Policy dialog box appears.
- Scheduler Pool – (Optional) Enter the name of a resource pool in the field. The
value you enter is used by the MapReduce Service you specified when Cloudera
Manager executes the MapReduce job for the replication. The job specifies the value
using one of these properties:
- MapReduce – Fair scheduler: mapred.fairscheduler.pool
- MapReduce – Capacity scheduler: queue.name
- YARN – mapreduce.job.queuename
- Maximum Map Slots - Limits for the number of map slots per mapper. The default value is 20.
- Maximum Bandwidth - Limits for the bandwidth per mapper. The default is 100 MB.
- Replication Strategy - Whether file replication tasks should be distributed among the mappers statically or dynamically. (The default is Dynamic.) Static replication distributes file replication tasks among the mappers up front to achieve a uniform distribution based on the file sizes. Dynamic replication distributes file replication tasks in small sets to the mappers, and as each mapper completes its tasks, it dynamically acquires and processes the next unallocated set of tasks.
To specify additional replication tasks, select .