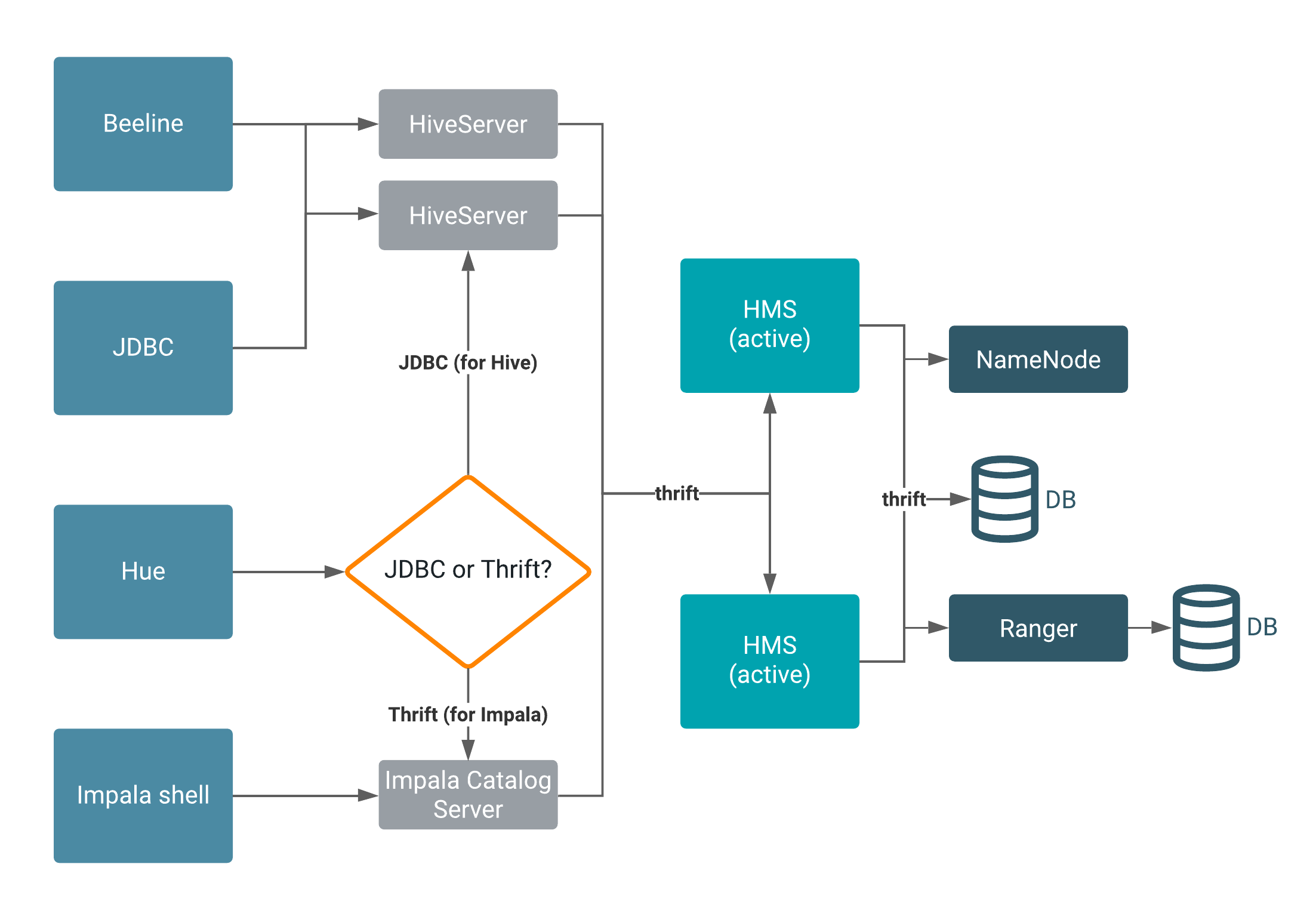
Hive metastore (HMS) is a service that stores metadata related to Apache Hive and other services,
in a backend RDBMS, such as MySQL or PostgreSQL. Impala, Spark, Hive, and other services share the
metastore. The connections to and from HMS include HiveServer, Ranger, and the
NameNode that represents HDFS.
Beeline, Hue, JDBC, and Impala shell clients make requests through thrift or JDBC to
HiveServer. The
HiveServer instance reads/writes data to HMS. By default, redundant HMS operate in active/active
mode. The physical data resides in a backend RDBMS, one for HMS. You must configure all HMS
instances to use the same backend database. A separate RDBMS supports the security service,
Ranger for example. All connections are routed to a single RDBMS service at any given time. HMS
talks to the NameNode over thrift and functions as a client to HDFS.
HMS connects directly to Ranger and the NameNode (HDFS), and so does HiveServer, but this is
not shown in the diagram for simplicity. One or more HMS instances on the backend can talk to
other services, such as Ranger.