Kudu network architecture
The highly scalable feature of Kudu is a result of Kudu's distributed nature. This topic describes how the logical components within a Kudu cluster interact with each other to achieve high availability and fault tolerance.
Kudu runs on a cluster of machines. These machines collectively store and manage Kudu's data. The cluster architecture is designed for fault tolerance and high availability. You can add more nodes to the Kudu cluster as your storage and throughput needs increase.
Kudu's architecture is based on tablets. A tablet contains a subset of the data in a table. Instead of storing the data in a table in a single location, Kudu distributes the table's tablets to multiple machines in the cluster. Those machines store the tablet's data on their local disks and respond to client requests to read and write table data. A Kudu cluster consists of one or more master nodes and one or more tablet servers. Tablet servers do most of the work in the cluster and typically run on machines known as worker nodes. Tablet servers are responsible for storing and processing data.
Kudu masters don't serve or store table data. They are responsible for the cluster's metadata, such as the schema for every table and on which tablet servers each table's data is stored.
System administrators have the option of setting up a Kudu cluster to be highly available. Therefore, if a single node becomes unavailable, it doesn't cause the entire cluster to be disabled and the applications will always have access to the data.
A highly-available cluster runs in a multi-master mode. A multi-master Kudu cluster has multiple masters, one of which is elected the leader by consensus of all the master nodes. To make sure leader election doesn't result in ties, clusters must have an odd number of masters. Leader masters are responsible for responding to client requests for data access. Masters that are not leaders are called followers. Followers keep their copy of the cluster metadata in sync with the leader, so that if a leader fails at any time, any of the followers can be elected by the remaining masters as the new leader.
High-availability is an optional feature that is useful when continuous access to the data is critical.
The following diagram shows a Kudu cluster with three masters and multiple tablet servers, each serving multiple tablets. It illustrates how Raft consensus is used to allow for both leaders and followers for both the masters and tablet servers. In addition, a tablet server can be a leader for some tablets and a follower for others. Leaders are shown in gold, while followers are shown in gray.
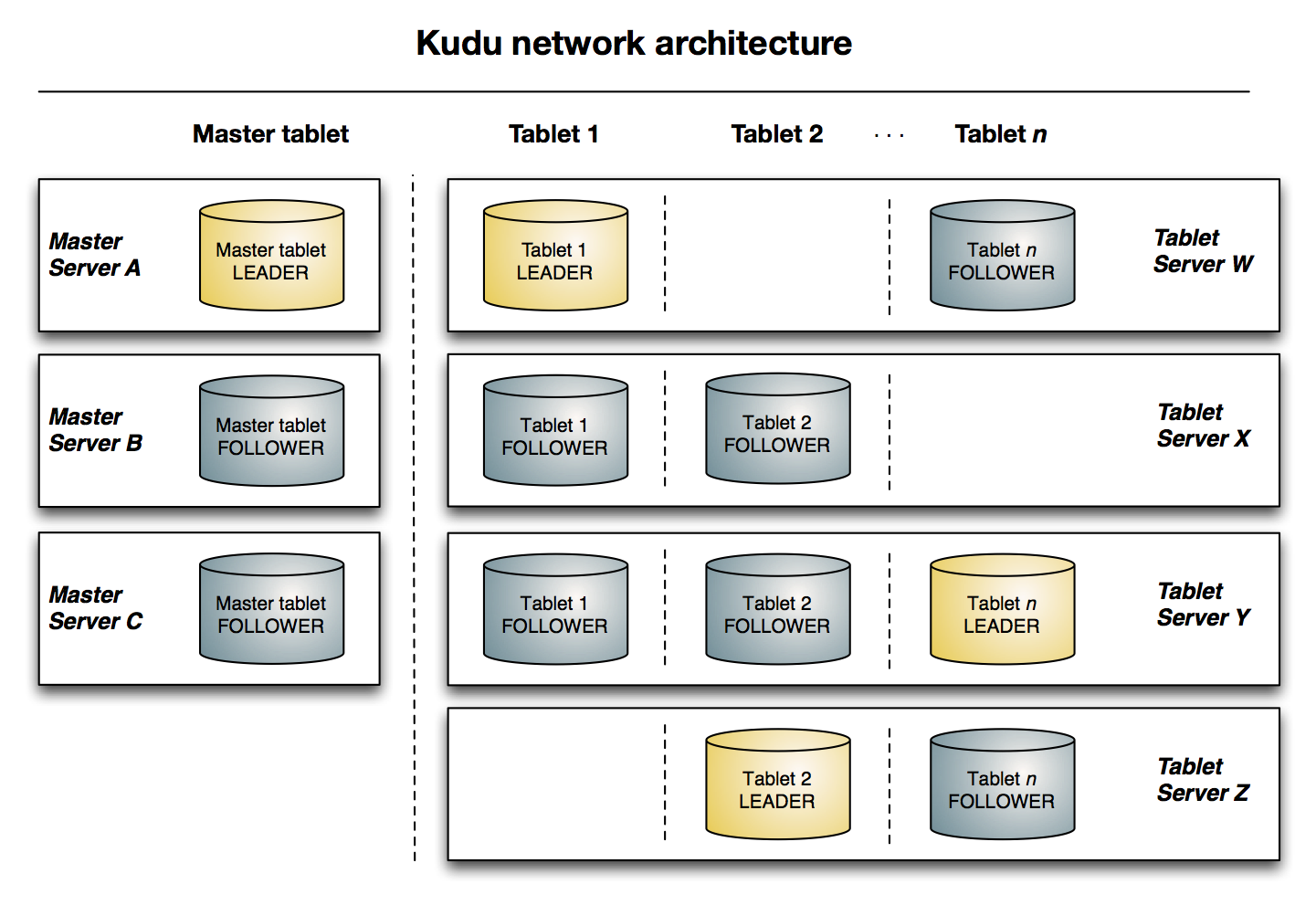
If the master fails when multi-master mode is disabled, tablet servers can continue to serve data as long as the required metadata from the master is cached. However, any requests to access data in tables for which the tablet servers don't have cached metadata will fail until a master is available again. Kudu masters are lightweight processes and can restart quickly.
A key feature to support fault tolerance is tablet replication, which ensures that data in a Kudu table will never be lost. By default, each tablet is replicated on three different servers. Each table can have its own setting for how many times its tablets should be replicated. Note that there must be enough tablet servers in the cluster to allow each replica to be stored on a separate server.
Among all of a tablet's replicas, one is elected leader by the tablet servers, the same way the cluster's Kudu masters elect a leader master. All other replicas are considered followers. Both followers and leaders can service reads, but only leaders can service a write operation.
The leader also propagates these operations to each of the follower replicas, who then perform the same operation with their own data, so that the follower and leader replicas are always in sync. In case a leader replica becomes unavailable, then the followers elect a new leader.
The default replication factor of three allows for continued operation if just one replica is unavailable. A replication factor of five can tolerate up to two unavailable replicas while still guaranteeing data availability.