The Cloud Storage Connectors
When deploying CDP clusters on cloud IaaS, you can take advantage of the native integration with the object storage services available on Amazon S3 on AWS . This integration is through cloud storage connectors included with CDP. Their primary function is to help you connect to, access, and work with data the cloud storage services.
The cloud connectors allow you to access and work with data stored in Amazon S3, including but not limited to the following use cases:
-
Collect data for analysis and then load it into Hadoop ecosystem applications such as Hive or Spark directly from cloud storage services.
-
Persist data to cloud storage services for use outside of CDP clusters.
-
Copy data stored in cloud storage services to HDFS for analysis and then copy back to the cloud when done.
-
Share data between multiple CDP clusters – and between various external non-CDP systems.
-
Back up CDP clusters using
distcp.
The cloud object store connectors are implemented as individual Hadoop modules. The libraries and their dependencies are automatically placed on the classpath.
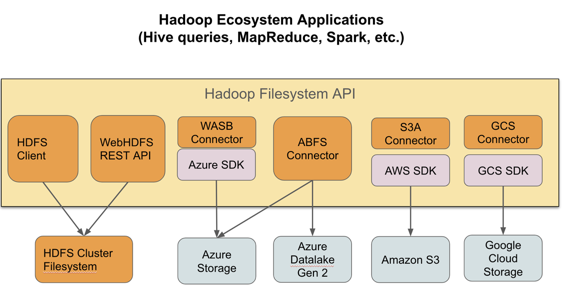
Amazon S3 is an object store. The S3A connector implements the Hadoop filesystem interface using AWS Java SDK to access the web service, and provides Hadoop applications with a filesystem view of the buckets. Applications can manipulate data stored in Amazon S3 buckets with an URL starting with the s3a:// prefix.
Amazon S3 can not be used as a replacement for HDFS as the cluster filesystem in CDP. Amazon S3 can be used as a source and destination of work.