HWC authorization
The way you configure Hive Warehouse Connector (HWC) affects the query authorization process and your security. There are a number of ways to access Hive through HWC, and not all operations go through HiveServer (HS2). Some operations, such as Spark Direct Reader and Hive Streaming, go to Hive directly through HMS where storage-based permissions generally apply.
| Capabilities | JDBC mode | Spark Direct Reader mode |
|---|---|---|
| Ranger integration with fine-grained access control | ✓ | N/A |
| Hive ACID reads | ✓ | ✓ |
| Workloads handled | Non-production workloads, small datasets | Production workloads, ETL without fine-grained access control |
- Direct Reader configuration: Connects to Hive Metastore (HMS)
- JDBC configuration: Connects to HiveServer (HS2) or HiveServer Interactive (HSI)
Ranger authorizes access to Hive tables from Spark through HiveServer (HS2), or the Hive metastore API (HMS API).
To write ACID managed tables from Spark to Hive, you must use HWC. To write external tables from Spark to Hive, you can use native Spark or HWC.
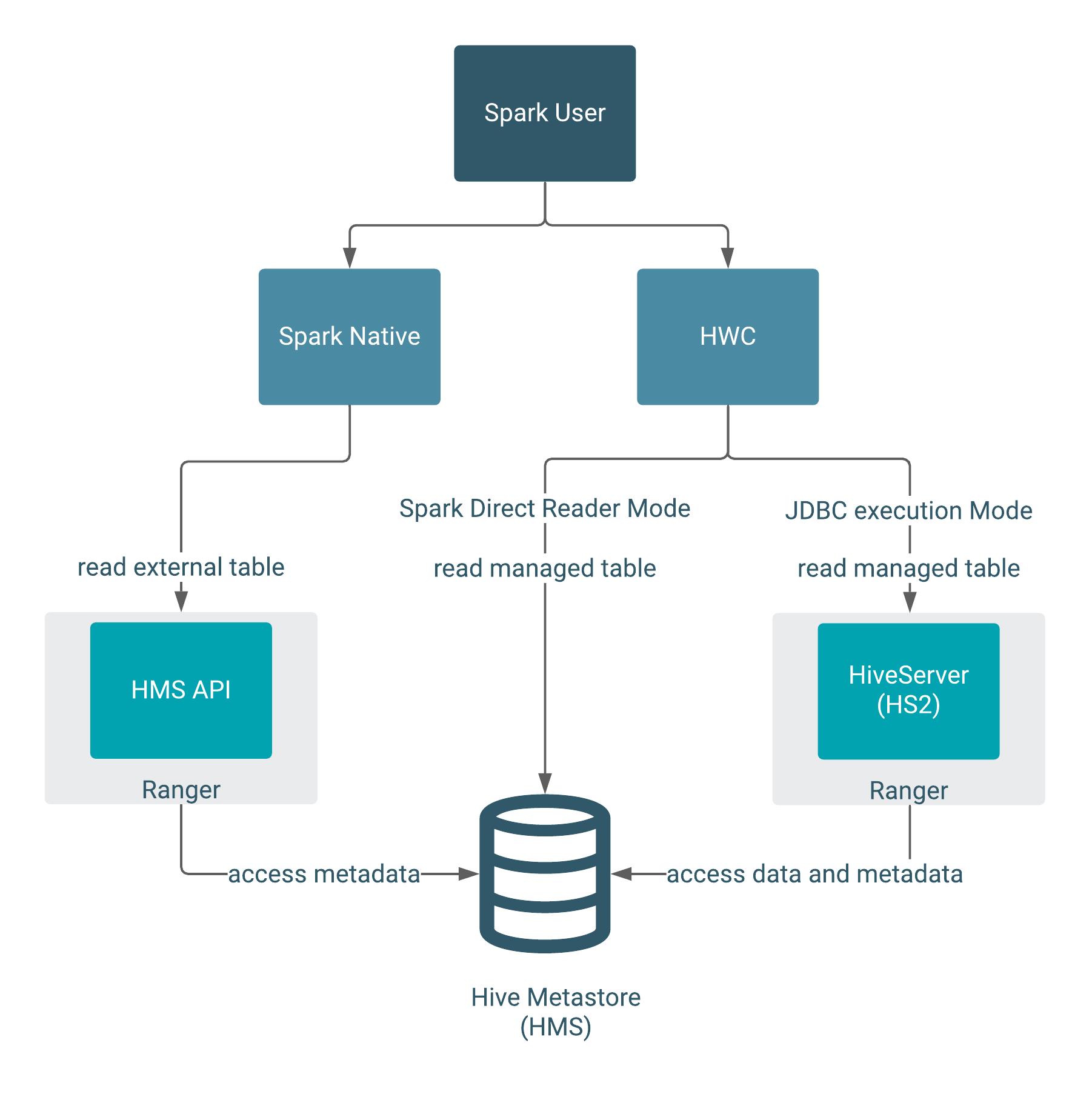
The following diagram shows the typical read authorization process:
The following diagram shows the typical write authorization process:
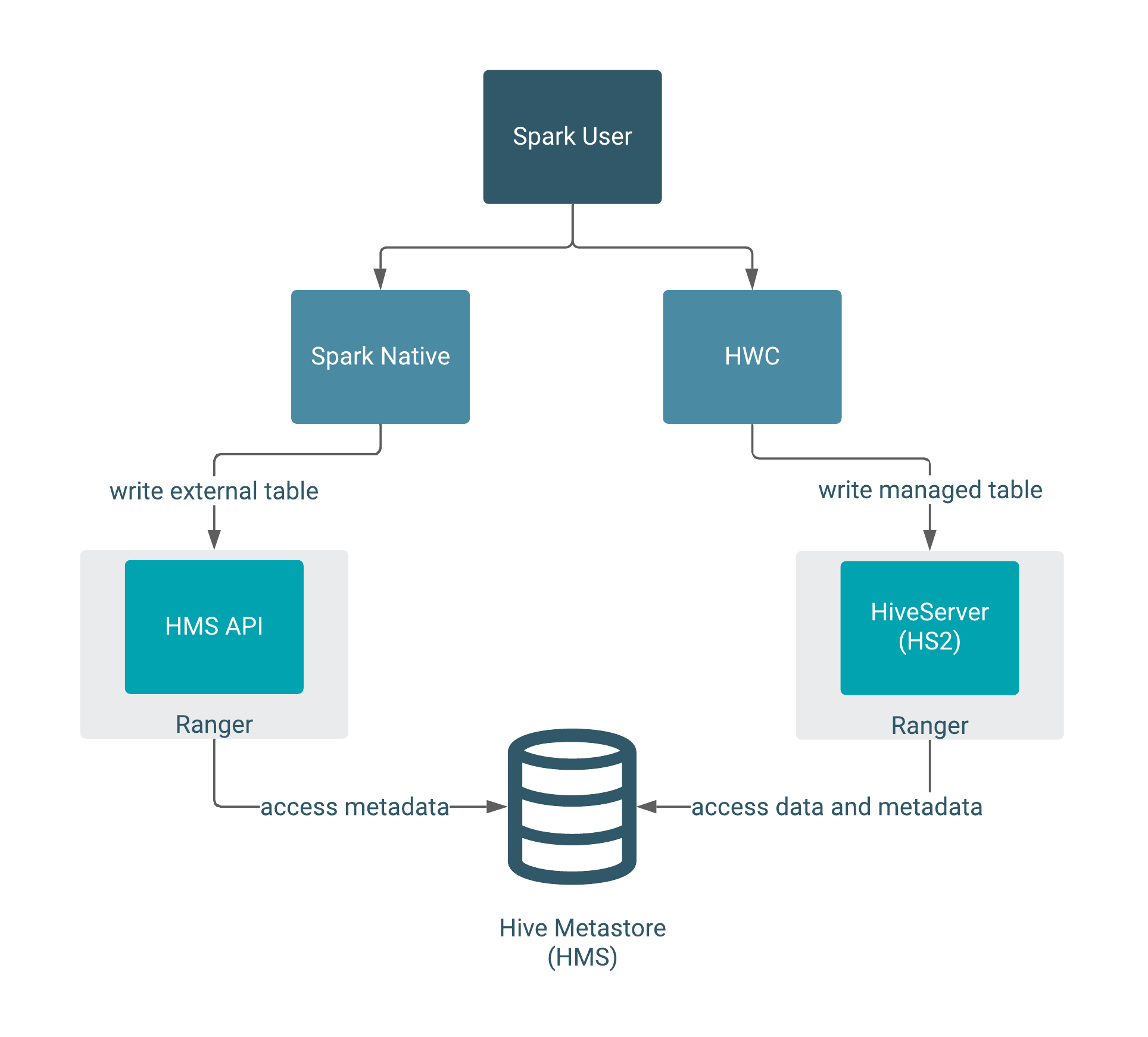
When writing, HWC always enforces authorization through HiveServer (HS2). Reading managed tables in JDBC mode enforces Ranger authorization, including fine-grained features, such as column mapping. In Direct Reader mode, the Ranger and HMS integration provides authorization.
External table queries go through the HMS API, which is also integrated with Ranger. If you do not use HWC, the Hive metastore (HMS) API, integrated with Ranger, authorizes external table access. HMS API-Ranger integration enforces the Ranger Hive ACL in this case. When you use HWC, queries such as DROP TABLE affect file system data as well as metadata in HMS.
Using the Direct Reader option, SparkSQL queries read managed table metadata directly from the HMS, but only if you have permission to access files on the file system. You cannot write to managed tables using the Direct Reader option.
Managed table authorization
A Spark job impersonates the end user when attempting to access an Apache Hive managed table. As an end user, you do not have permission to access, managed files in the Hive warehouse. Managed tables have default file system permissions that disallow end user access, including Spark user access.
As Administrator, you set permissions in Ranger to access the managed tables when you configure HWC for JDBC reads. You can fine-tune Ranger to protect specific data. For example, you can mask data in certain columns, or set up tag-based access control.
When you configure HWC for Direct Reader mode, you cannot use Ranger in this way. You must
set read access to the file system location for managed tables. You must have Read and Execute
permissions on the Hive warehouse location
(hive.metastore.warehouse.dir).
External table authorization
Ranger authorization of external table reads and writes is supported. You need to configure a few properties in Cloudera Manager for authorization of external table writes. You must be granted file system permissions on external table files to allow Spark direct access to the actual table data instead of just the table metadata.
Direct Reader Authorization Limitation
As Spark allows users to run arbitrary code, Ranger fine grained access control, such as row level filtering or column level masking, is not possible within Spark itself. This limitation extends to data read using Direct Reader.
To restrict data access at a fine-grained level, use a read option that supports Ranger. Only consider using the Direct Reader option to read Hive data from Spark if you do not require fine-grained access. For example, use Direct Reader for ETL use cases.