You can read and write Hive ACID tables from a Spark application using Zeppelin, a
browser-based GUI for interactive data exploration, modeling, and visualization.
You must be running spark application and have all the appropriate permissions to read the data from the hive warehouse directory for managed (ACID) tables.
-
Open the livy configuration file on the livy node and configure HWC Spark Direct Reader mode.
%livy2.conf
...
livy.spark.hadoop.hive.metastore.uris thrift://hwc-secure-1.hwc-secure.root.hwx.site:9083
livy.spark.jars local:/opt/cloudera/parcels/CDH-7.2.1-1.cdh7.2.1.p0.4847773/jars/hive-warehouse-connector-assembly-<version>.jar
livy.spark.kryo.registrator com.qubole.spark.hiveacid.util.HiveAcidKyroRegistrator
livy.spark.security.credentials.hiveserver2.enabled true
livy.spark.sql.extensions com.hortonworks.spark.sql.rule.Extensions
livy.spark.sql.hive.hiveserver2.jdbc.url jdbc:hive2://hwc-secure-1.hwc-secure.root.hwx.site:2181/default;retries=5;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
livy.spark.sql.hive.hiveserver2.jdbc.url.principal hive/_HOST@ROOT.HWX.SITE
...
-
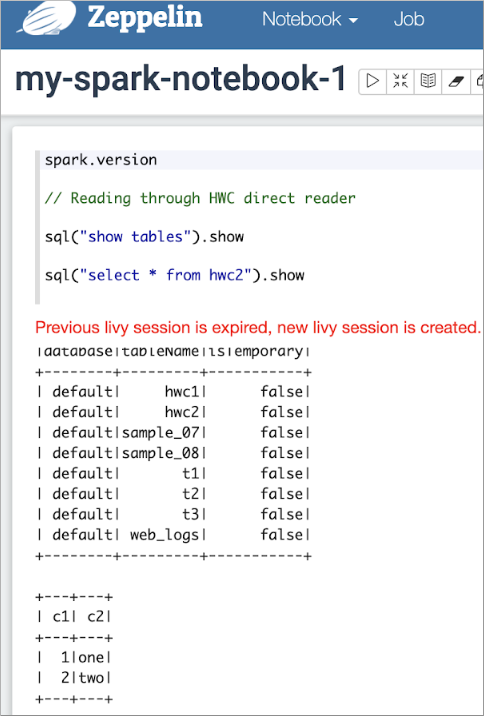
In a Zeppelin notebook, read a Hive ACID table.
sql("show tables").show
sql("select * from hwc2").show
-
Perform a batch write from Spark.
val hive = com.hortonworks.hwc.HiveWarehouseSession.session(spark).build()
val df = Seq(
(1, "a", 1.1),
(2, "b", 2.2),
(3, "c", 3.3)
).toDF("col1", "col2", "col3")
val tableName = "t3"
hive.dropTable(tableName, true, true)
df.write.format("com.hortonworks.spark.sql.hive.llap.HiveWarehouseConnector").mode("append").option("table", tableName).save()
-
Read data from table t3.
sql("select * from t3").show
Output is:
tableName: String = t3
+----+----+----+
|col1|col2|col3|
+----+----+----+
| 1| a| 1.1|
| 2| b| 2.2|
| 3| c| 3.3|
+----+----+----+