Creating a Hive external table replication policy
You must set up your clusters before you create a Hive/Impala replication policy. You can also use CDP Private Cloud Base Replication Manager to replicate Hive/Impala data to cloud, however you cannot replicate data from one cloud instance to another using Replication Manager.
Before you create a Hive external table replication policy, you must consider when to specify the hosts to improve performance, understand how DDL commands affect Hive tables during replication, how to disable parameter replication in Cloudera Manager, and the additional properties to configure for Hive replication in dynamic environments. For more information, see Hive external table replication policy considerations.
To replicate Hive/Impala data to cloud, you must have the appropriate credentials to access the cloud account. Additionally, you must create buckets in S3 or data lake store in ADLS. Replication Manager backs up file metadata, including extended attributes and ACLs when you replicate data to cloud storage.
- Replication policies can be set up on files or directories in HDFS and on external tables in Hive—without manual translation of Hive datasets to HDFS datasets, or vice versa. Hive Metastore information is also replicated.
- Applications that depend on external table definitions stored in Hive, operate on both replica and source as table definitions are updated.
- Set the Ranger policy for hdfs user on target cluster to
perform all operations on all databases and tables. The same user role is used to import
Hive Metastore. The hdfs user should have access to all Hive
datasets, including all operations. Otherwise, Hive import fails during the replication
process. To provide access, perform the following steps:
- Log in to Ranger Admin UI.
- Go to the section, and provide hdfs user permission to the all-database, table, column policy name.
- On the target cluster, the hive user must have Ranger admin privileges. The same hive user performs the metadata import operation.
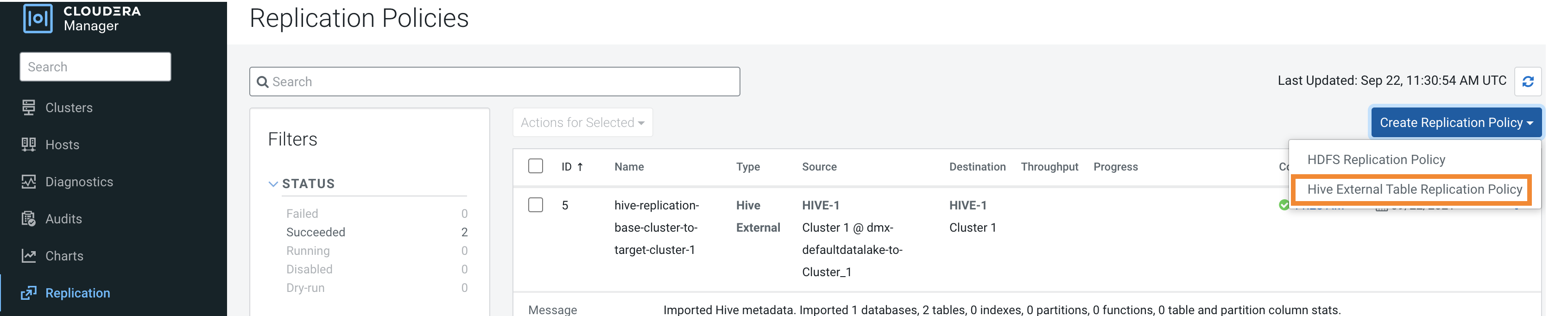
- Go to the page, click Create Replication Policy.
- Select Hive External Table Replication Policy.
- If your replication job takes a long time to complete, see Improve network latency during replication job run to improve network latency.
- If files change before the replication finishes, the replication might fail. For more information, see Guidelines to add or delete source data during replication job run.
- For efficient replication, consider making the Hive Warehouse Directory and the directories of any external tables snapshottable, so that the replication job creates snapshots of the directories before copying the files. For more information, see Hive/Impala replication using snapshots and Guidelines to use snapshot diff-based replication.
- If your cluster has Hive clients installed on hosts with limited resources and the Hive/Impala replication policies use these hosts to run commands for the replication, the replication job performance might degrade. To specify the hosts to use during replication so that the lower-resource hosts are not used to improve the replication job performance, see Specifying hosts to improve Hive replication policy performance.