Creating Hive ACID table replication policy
You can create a Hive ACID replication policy after you set up the environment and configure the required parameters.
- Go to the Replication > Replication Policies page in the Cloudera Manager for the target cluster where the peer is set up.
- Click Create Replication Policy.
-
Select Hive ACID Table Replication Policy.
The following sample image shows the Hive ACID Table Replication Policy option on the Replication Policies page in Cloudera Manager:
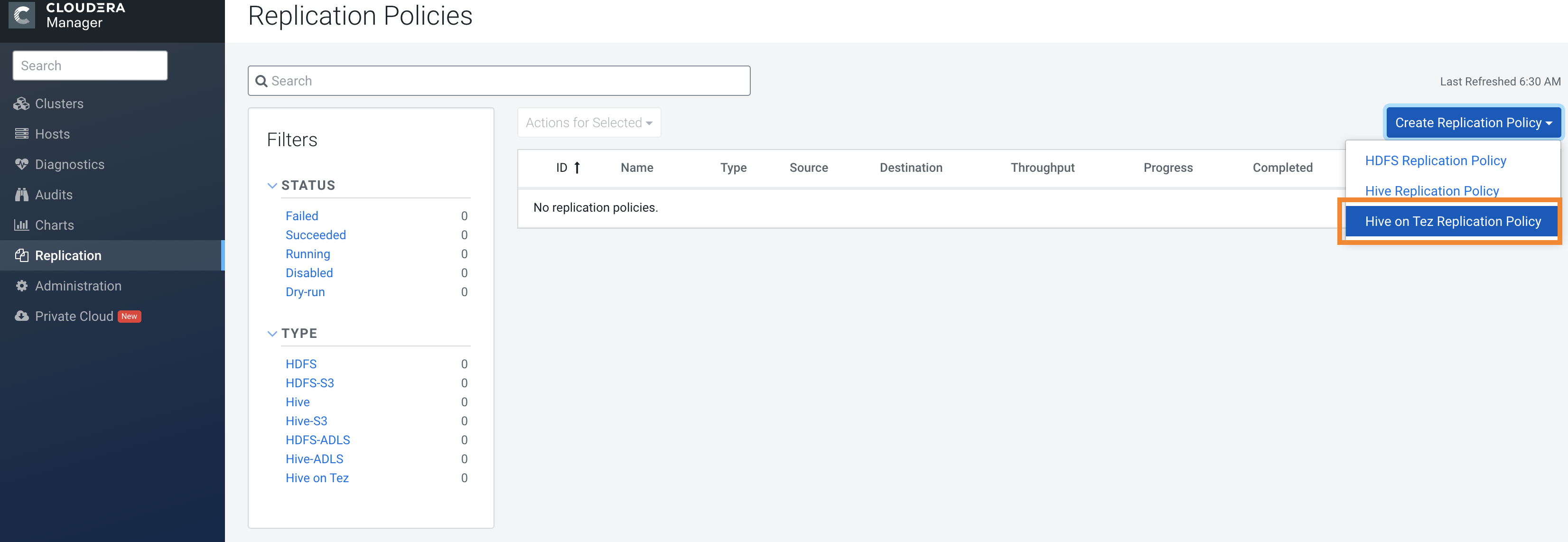 The Create Hive ACID Table Replication Policy wizard appears.
The Create Hive ACID Table Replication Policy wizard appears. -
In the General tab, configure the following options:
Option Action to perform Policy Name Enter a unique name for the replication policy. Source Choose the source cluster. Destination Choose the target cluster. Destination Staging Path Enter a valid path to the staging location. The path must have the required permissions for the hive user. For example: /user/hive/data. Hive ACID table replication policy uses a common staging location on the source or target cluster. After you enter a valid path to the staging location, the hive.repl.rootdir parameter is configured with this path. The REPL DUMP command dumps data in the staging location in the source cluster. The REPL LOAD command reads the data from the staging location. The REPL DUMP command runs in the source cluster and the REPL LOAD command runs in the target cluster.
Source Database Enter the source database name. Schedule Schedule the replication job as necessary. The Hive ACID table replication policy uses the Hive scheduler to schedule the replication policies. You can choose the following schedule options:- Every - Choose an
interval. The schedule starts at the next exact
interval based on the server time. If you want to
start it immediately, issue a Run
Now operation.
For example, if you are in California and the destination cluster is in the Europe (Frankfurt) region, the schedule is set based on the server time, that is, Frankfurt local time.
- Unix Cron Expression -
Enter a valid Unix cron expression.
You can generate the Unix cron expression in the following page, and then use it in the Create Hive ACID Table Replication Policy wizard:
https://www.freeformatter.com/cron-expression-generator-quartz.html
For example, you can use 0 */30 * ? * * to schedule the policy to run every 30 minutes, 0 0 */4 ? * * to schedule the run for every 4 hours, or 0 0 0 * * ? every day at midnight.
Run as Username Enter hive. - Every - Choose an
interval. The schedule starts at the next exact
interval based on the server time. If you want to
start it immediately, issue a Run
Now operation.
-
Click the Resources tab to configure the following
options:
Option Description Scheduler Pool (Optional) Enter the name of a resource pool. The value you enter is used by the MapReduce Service when Cloudera Manager runs the MapReduce job for the replication. You can use one of the following property:
- MapReduce – Fair scheduler: mapred.fairscheduler.pool
- MapReduce – Capacity scheduler: queue.name
- YARN – mapreduce.job.queuename
Maximum Number of Copy Mappers Enter the maximum number of simultaneous copy mappers for DistCp. The default value is 20. Maximum Bandwidth per Copy Mapper Enter the bandwidth limit for each mapper. Default is 100 MB. The total bandwidth used by the replication policy is equal to Maximum Bandwidth multiplied by Maximum Map Slots. Therefore, you must ensure that the bandwidth and map slots you choose do not impact other tasks or network resources in the target cluster.
-
Select the Advanced tab to configure the following
options:
Option Description Policy Description (Optional). Enter a brief description for the replication policy. Overrides Enter key-value pairs to override parameters for Hive ACID table replication configuration. For example, when you use HA-based clusters, you can enter the relevant key-value pairs. During the replication process, the Replication Manager overrides the key-values pairs. You can also pass the DistCp argument.
- Click Save to run the Hive ACID table replication policy.
- Go to the error log path.
- Search for the file named _non_recoverable.
- Check the error stack that is printed in the _non_recoverable file.
- Fix the error.
- Delete the _non_recoverable file. For the next replication
jobs in the policy to function normally, the
_non_recoverablefile must be deleted.