Writing data to Ozone in a Kerberos and TLS/SSL enabled cluster with Kafka Connect
You can use the HDFS Sink Connector developed by Cloudera to write Kafka topic data to Ozone in a secure cluster. Connector deployment and configuration is done using the SMM UI.
The following steps walk you through how the Cloudera-developed HDFS Sink Connector can be set up and deployed using the SMM UI.
In addition to the connector setup, these steps also describe how you can create a test topic and populate it with data using Kafka command line tools. If you already have a topic that is ready for use and do not want to create a test topic, you can skip steps 1 through 3. These steps deal with topic creation, message consumption, and message production. They are not necessary to carry out.
- Ensue that a Kerberos and TLS/SSL enabled CDP PvC Base cluster with Kafka, SMM, and Ozone is set up and configured.
- To
create a test topic with the Kafka console tools, you must ensure that a
.propertiesclient configuration file is available for use.You can create one using the following example as a template:sasl.jaas.config=com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true keyTab="[***PATH TO KEYTAB FILE***]" principal="[***KERBEROS PRINCIPAL***]"; security.protocol=SASL_SSL sasl.mechanism=GSSAPI sasl.kerberos.service.name=kafka ssl.truststore.location=[***TRUSTSTORE LOCATION***]
- Verify that connector deployment is successful:
- Click on either the topic or the connector you created. If connector deployment is successful, a flow is displayed between the topic you specified and the connector you created.
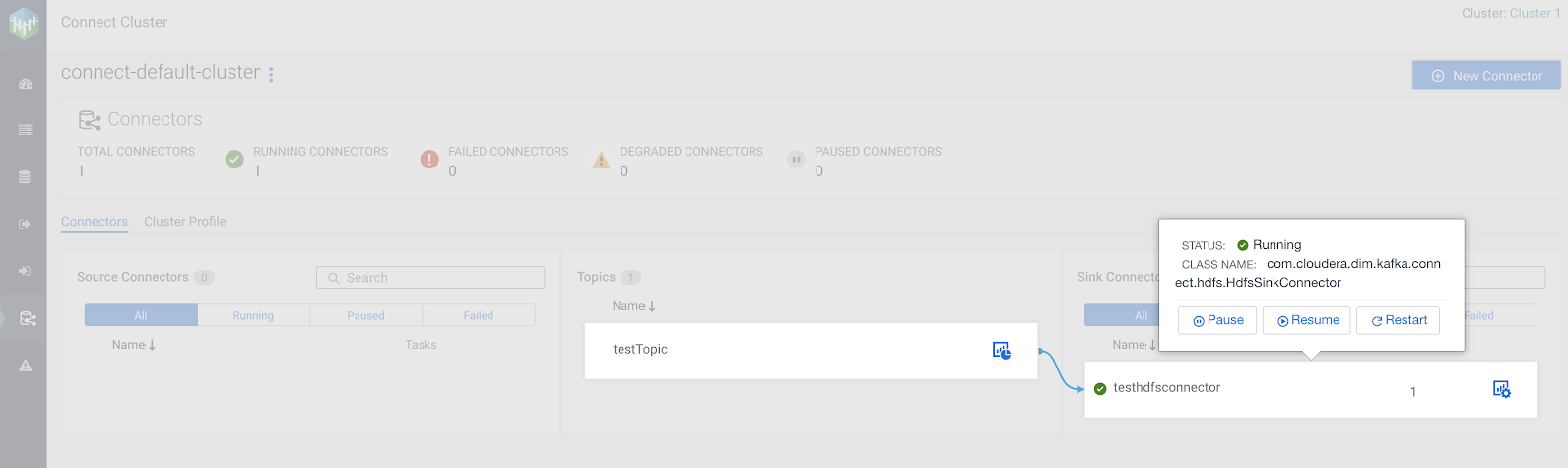
- Click on either the topic or the connector you created.