Configuring Resource Parameters
After enabling cgroups, you can restrict and limit the resource consumption of roles (or role groups) on a per-resource basis by using resource allocation configuration parameters.
Minimum Required Role: Cluster Administrator (also provided by Full Administrator)
- Before you begin:
- OPSAPS-74341: NodeManagers might fail to start during the cluster restart after the Cloudera Manager 7.13.1.x upgrade
Steps:
- In the Cloudera Manager Admin Console, go to the service where you want to configure resources.
- Click the Configuration tab.
- Select .
- Locate the resource allocation configuration parameters that start with
Cgroup V1 (if you are using cgroup v1) or Cgroup
V2 (if you are using cgroup v2). You can specify resource allocations for
each type of resource (CPU, memory, etc.) for all roles of the service using these
parameters, or you can specify different allocations for each role by clicking the
Edit Individual Values link. Edit any of the following
parameters:
- Cgroup V1 parameters:
- Cgroup V1 CPU Shares - The more CPU shares given to a role, the larger its share of the CPU when under contention. Until processes on the host (including both roles managed by Cloudera Manager and other system processes) are contending for all of the CPUs, this will have no effect. When there is contention, those processes with higher CPU shares will be given more CPU time. The effect is linear: a process with 4 CPU shares will be given roughly twice as much CPU time as a process with 2 CPU shares.
- Cgroup V1 BLKIO Weight - The greater the I/O weight, the
higher priority will be given to I/O requests made by the role when I/O is under
contention (either by roles managed by Cloudera Manager or by other system
processes).
This only affects read requests; write requests remain unprioritized. The Linux I/O scheduler controls when buffered writes are flushed to disk, based on time and quantity thresholds. It continually flushes buffered writes from multiple sources, not certain prioritized processes.
- Cgroup V1 Memory Soft Limit - When the limit is reached, the kernel will reclaim pages charged to the process if and only if the host is facing memory pressure. If reclaiming fails, the kernel may stop the process. Both anonymous as well as page cache pages contribute to the limit.
- Cgroup V1 Memory Hard Limit - When a role's resident set
size (RSS) exceeds the value of this parameter, the kernel will swap out some of
the role's memory. If it is unable to do so, it will stop the process. The kernel
measures memory consumption in a manner that does not necessarily match what the
toporpsreport for RSS, so expect that this limit is a rough approximation.
- Cgroup V2 parameters:
- Cgroup V2 CPU Weight - The more CPU weight given to a role in cgroup V2, the larger its share of the CPU when under contention. Until processes on the host (including both roles managed by Cloudera Manager and other system processes) are contending for all of the CPUs, this setting will have no effect. When there is contention, those processes with higher CPU weights will be given more CPU time. The allocation is proportional: a role with a CPU weight of 200 will receive twice as much CPU time as a role with a weight of 100.
- Cgroup V2 I/O Weight - The greater the I/O weight
assigned to a role in cgroup V2, the higher priority its I/O requests will receive
when there is contention for I/O resources. This means that roles with higher I/O
weights will have their read and write requests processed more frequently compared
to roles with lower weights, improving their overall performance under I/O
contention.
Unlike cgroup V1, cgroup V2 prioritizes both read and write requests, allowing for a more balanced resource allocation. The impact is proportional: a role with an I/O weight of 200 will have its requests prioritized over a role with a weight of 100.
- Cgroup V2 Memory Soft Limit - In cgroup V2, the memory soft limit allows a role to use memory up to a specified limit, with leniency under normal conditions. If the host experiences memory pressure, the kernel will preferentially reclaim memory from processes that exceed their soft limits, attempting to free up space. If reclamation is unsuccessful and memory pressure remains, then the kernel might kill processes to alleviate the situation. Both anonymous and page cache pages count towards this limit, influencing which memory is reclaimed. Unlike hard limits, this approach provides flexibility under low memory pressure, while still protecting system stability during high memory usage scenarios.
- Cgroup V2 Memory Hard Limit - In cgroup V2, the memory hard limit strictly confines a role's memory usage to the specified value. When the memory consumption of a role, including its Resident Set Size (RSS), exceeds this limit, the kernel will attempt to swap out some of the role's memory to stay within bounds. If swapping is not sufficient or feasible, the kernel will terminate the process to enforce the limit. Memory consumption is tracked more comprehensively than what utilities like top or ps report for RSS, so the hard limit serves as a strict boundary rather than an exact match to these metrics.
- Cgroup V1 parameters:
- Click Save Changes.
- Restart the service or roles where you changed values.
See Restarting a Cloudera Runtime Service or Starting, Stopping, and Restarting Role Instances.
Protecting Production MapReduce Jobs from Impala Queries
- The cluster is using homogenous hardware
- Each worker host has two cores
- Each worker host has 8 GB of RAM
- Each worker host is running a DataNode, TaskTracker, and an Impala Daemon
- Each role type is in a single role group
- Cgroups-based resource management has been enabled on all hosts
| Action | Procedure |
|---|---|
| CPU |
|
| Memory |
|
| I/O |
|
- When MapReduce jobs are running, all Impala queries together will consume up to a fifth of the cluster's CPU resources.
- Individual Impala Daemons will not consume more than 1 GB of RAM. If this figure is exceeded, new queries will be cancelled.
- DataNodes and TaskTrackers can consume up to 1 GB of RAM each.
- We expect up to 3 MapReduce tasks at a given time, each with a maximum heap size of 1 GB of RAM. That's up to 3 GB for MapReduce tasks.
- The remainder of each host's available RAM (6 GB) is reserved for other host processes.
- When MapReduce jobs are running, read requests issued by Impala queries will receive a fifth of the priority of either HDFS read requests or MapReduce read requests.
Operating System Support for Cgroups
Cgroups are a feature of the Linux kernel, and as such, support depends on the host's Linux distribution and version as shown in the following tables. If a distribution lacks support for a given parameter, changes to the parameter have no effect.
The exact level of support can be found in the Cloudera Manager Agent log file, shortly after the Agent has started. In the log file, look for an entry like this:
Found cgroups capabilities: {
'has_blkio': False, 'has_io': True, 'has_cpu': True, 'has_cpuacct': False,
'has_memory': True, 'has_devices': False, 'default_blkio_weight': -1,
'default_io_weight': -1, 'default_cpu_shares': -1, 'default_cpu_weight': -1,
'default_cpu_max': -1, 'default_cpu_rt_runtime_us': -1, 'default_memory_limit_in_bytes': -1,
'default_memory_max': -1, 'default_memory_soft_limit_in_bytes': -1,
'default_memory_high': -1, 'writable_cgroup_dot_procs': False}The has_cpu and similar entries correspond directly to
support for the CPU, I/O, and memory parameters.
Verifying Cgroup Configuration Changes
When managing services through Cloudera Manager 7.13.1.x, any cgroup-related configuration changes made on a service's Configuration page are applied instantly and directly to the corresponding controller files on the relevant hosts. This allows for immediate verification of changes without requiring a service restart or waiting for stale configuration indicators.
To confirm that your cgroup configurations have taken effect:
- Locate the Configuration: Navigate to the Configuration page for your desired service such as YARN.
- Modify a Cgroup Setting: Update any Cgroup-related parameter such as Cgroup V2 CPU Weight for JobHistory roles as shown in the following figure.
- Instant Reflection: The changes are immediately written to the respective Cgroup
controller files on the host where the role is running.
Figure 1. Verifying YARN JobHistory for Cgroup V2 CPU Weight 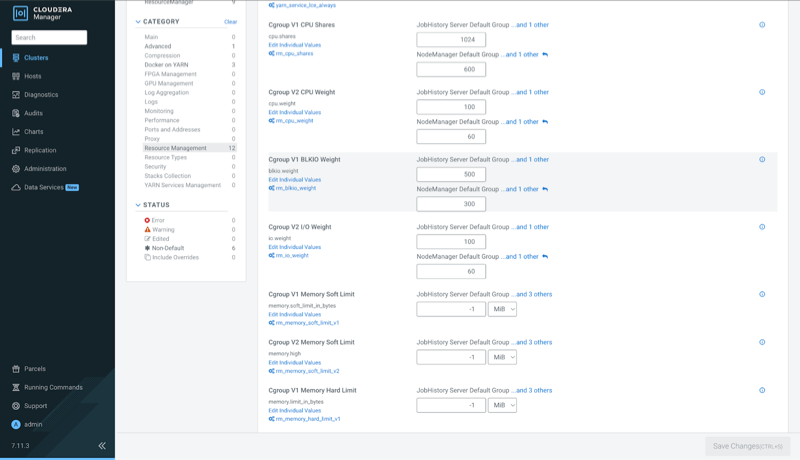
Suppose you are viewing the Cgroup configurations on YARN's configuration page. If you modify the cpu.weight value:
Any changes you make in Cloudera Manager to Cgroup V2 CPU Weight for this role will instantly update this file, which you can verify with the following cat command:# SSH into the relevant host where the JobHistory role is running # Navigate to the cGroup directory for the JobHistory service [root@bofa-testcgroups1-1 cgroup]# cd /sys/fs/cgroup/330-yarn-JOBHISTORY # View the current cpu.weight value in the controller file [root@bofa-testcgroups1-1 330-yarn-JOBHISTORY]# cat cpu.weight 100