View HDFS directory structure of Compute clusters
Learn how to view the HDFS structure in a Base cluster from a Compute cluster.
In a Virtual Private Cluster environment, some Compute clusters have a local HDFS. But, crucial directories (JHS for spark, logging for yarn) for compute services are created in the Base cluster HDFS.
One of the design assumptions of Compute clusters is that they would be transient and so the user should still have a way to access important logs after the Compute clusters have been destroyed.
- Open the Cloudera Manager Admin Console and
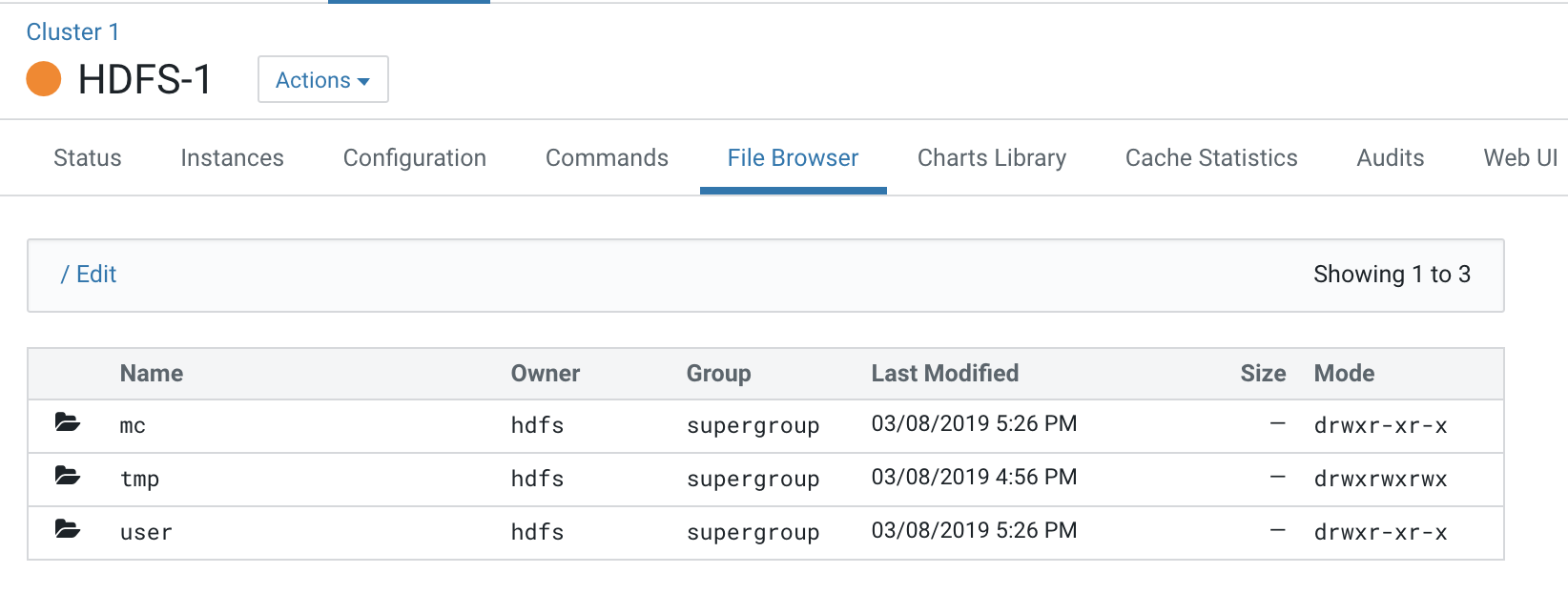
view the HDFS hierarchy on the Base cluster HDFS service by opening the
File Browser: .
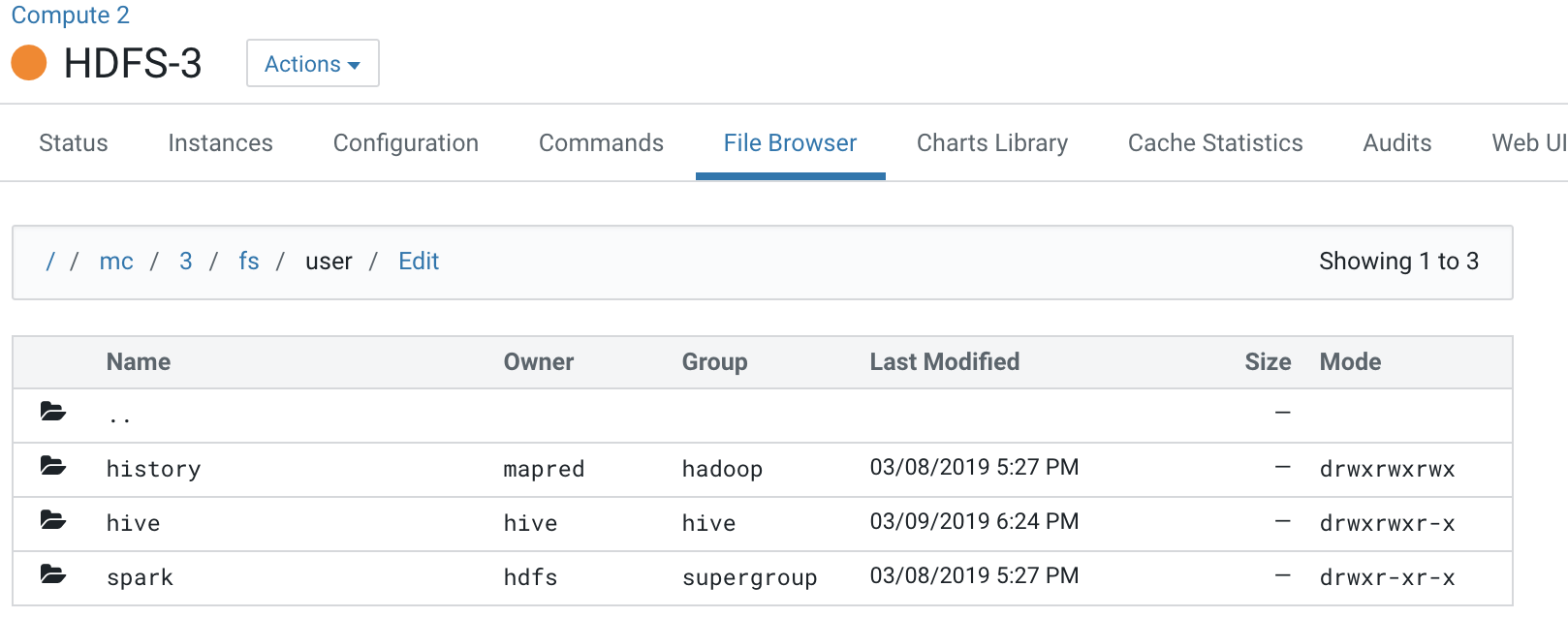
All the logs pertaining to Compute clusters are under the “mc” directory.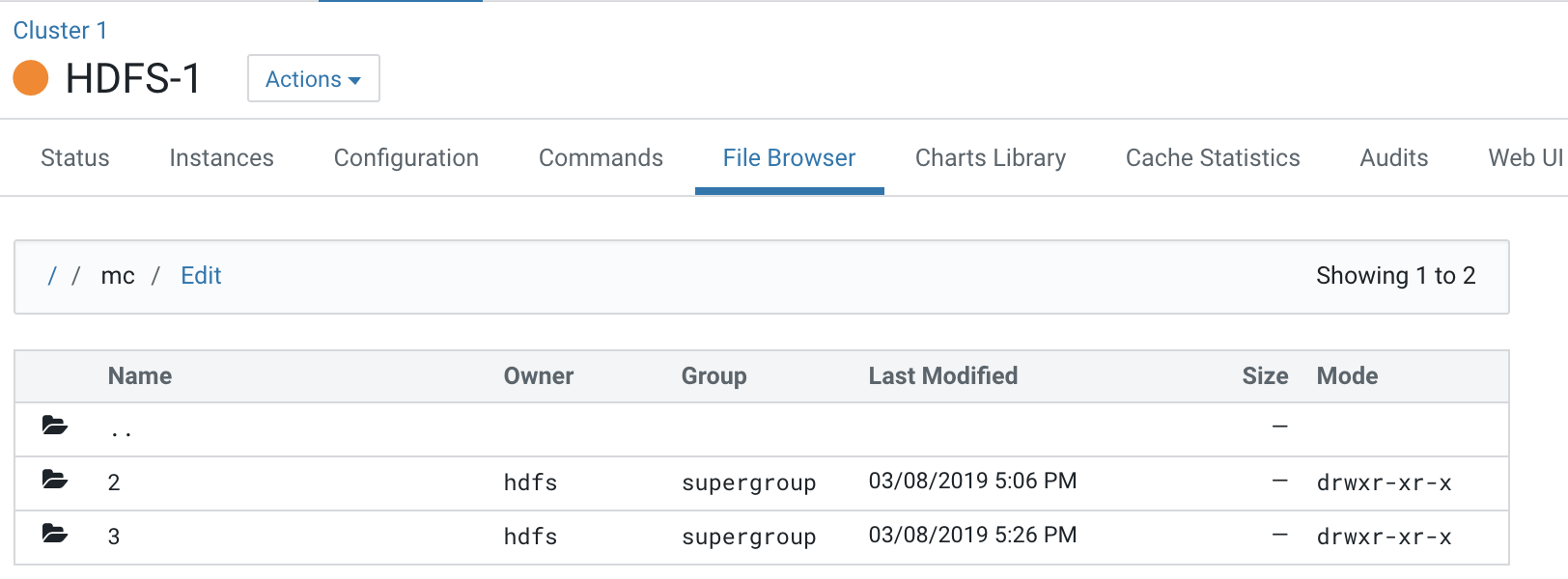
This Base cluster has 2 Compute clusters associated with it, Compute 1 and Compute 2.
Each Compute cluster (based on its ID) gets a folder under this directory, so folder 2 belongs to Compute 1 and 3 belongs to Compute 2. The ID of the cluster can be identified from the URL used to access the cluster. Click on Compute 1 in the CM Cluster view and inspect the URL.
http://quasar-wfrgnj-1.vpc.cloudera.com:7180/cmf/clusters/2/statusThe ID is the segment following
/clustersin the URL. This is also the subfolder name under the/mcfolder.This is the directory where all the logs for services in Compute 1 are stored.
- Navigate to the file browser of a Compute
cluster.
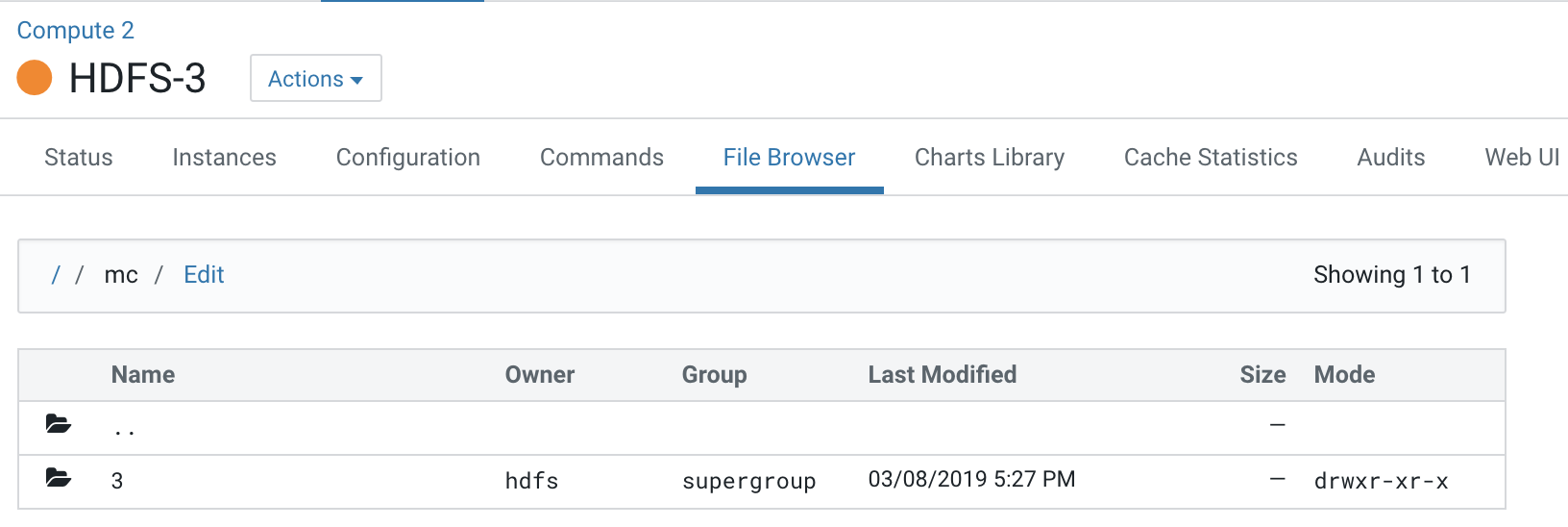
Note that folder 2 which is dedicated for the Compute 1 cluster is not visible to the Compute 2 cluster.
Navigating to folders below this hierarchy, you can see the folders created for services present on the Compute 2 cluster.