Using the Livy API to run Spark jobs
Using the Livy API to run Spark jobs is similar to using the original Spark API. Livy provides programmatic API and REST API.
Programmatic API
Livy provides a programmatic Java/Scala and Python API that allows applications to run code inside Spark without having to maintain a local Spark context. For more information, see Using the Programmatic API documentation.
REST API
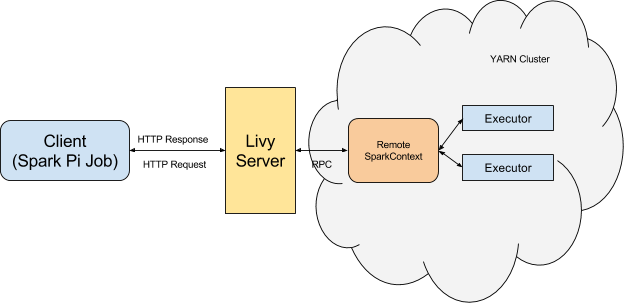
Architecturally, the client creates a remote Spark cluster, initializes it, and submits jobs through REST APIs. The Livy server unwraps and rewraps the job, and then sends it to the remote SparkContext through RPC. While the job runs the client waits for the result, using the same path. The following diagram illustrates the process: