When Shuffles Do Not Occur
In some circumstances, the transformations described previously do not result in shuffles. Spark does not shuffle when a previous transformation has already partitioned the data according to the same partitioner. Consider the following flow:
rdd1 = someRdd.reduceByKey(...)
rdd2 = someOtherRdd.reduceByKey(...)
rdd3 = rdd1.join(rdd2)
Because no partitioner is passed to reduceByKey, the default
partitioner is used, resulting in rdd1 and rdd2 both
being hash-partitioned. These two reduceByKey transformations result
in two shuffles. If the datasets have the same number of partitions, a join requires
no additional shuffling. Because the datasets are partitioned identically, the set of
keys in any single partition of rdd1 can only occur in a single
partition of rdd2. Therefore, the contents of any single output
partition of rdd3 depends only on the contents of a single partition
in rdd1 and single partition in rdd2, and a third
shuffle is not required.
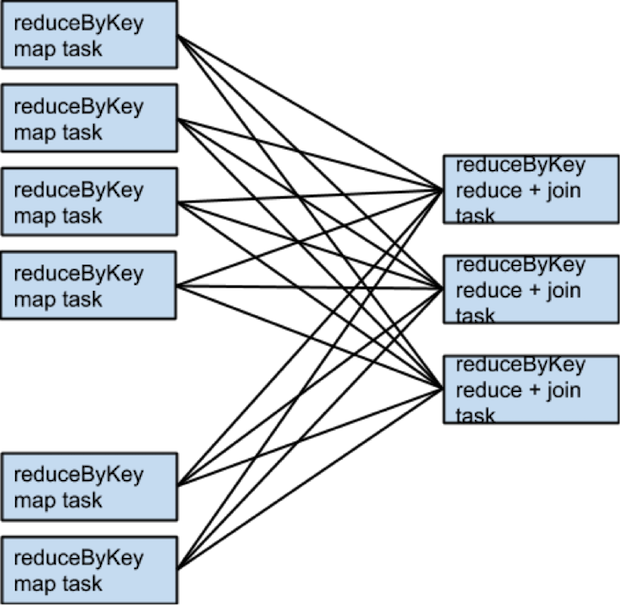
For example, if someRdd has four partitions,
someOtherRdd has two partitions, and both the
reduceByKeys use three partitions, the set of tasks that run would
look like this:
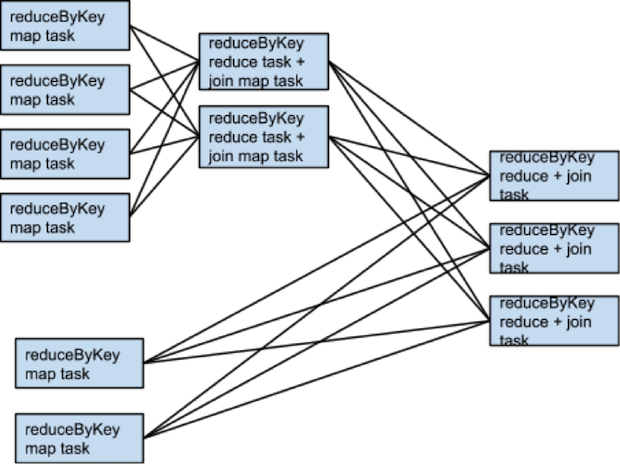
If rdd1 and rdd2 use different partitioners or use
the default (hash) partitioner with different numbers of partitions, only one of the
datasets (the one with the fewer number of partitions) needs to be reshuffled for the
join:
To avoid shuffles when joining two datasets, you can use broadcast variables. When one of the datasets is small enough to fit in memory in a single executor, it can be loaded into a hash table on the driver and then broadcast to every executor. A map transformation can then reference the hash table to do lookups.