Error Messages and Various Failures
How to resolve or work around issues that present the listed symptoms and possible causes.
HDFS contentSummary calls locked
Symptom: contentSummary calls in HDFS locking for tens or hundreds of seconds. The locking effectively makes HDFS unusable in the worst cases. In the least impact cases, the call locking negatively impacts performance.
Possible cause: These calls are blocked in Ranger code when performing a recursive permission check.
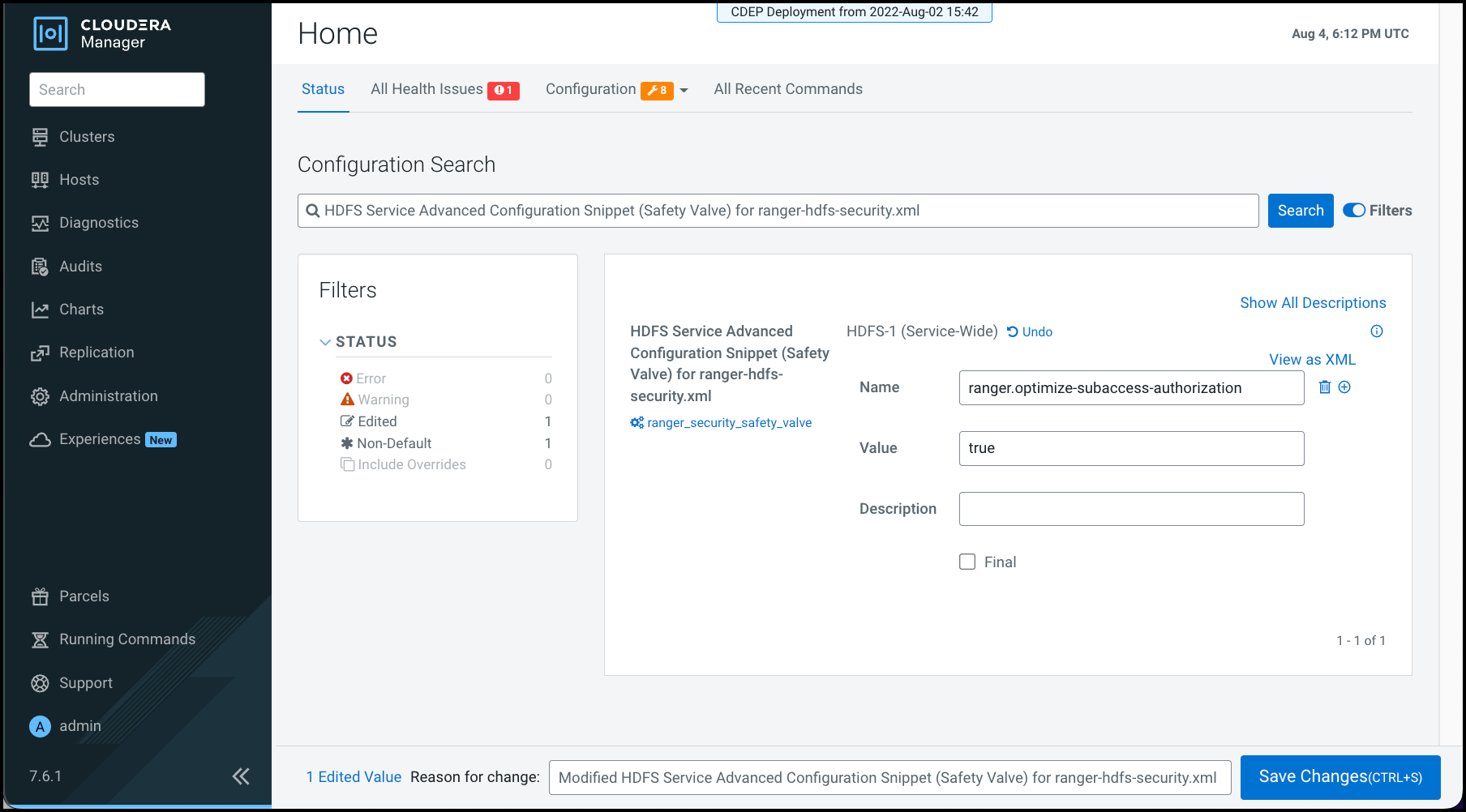
Steps to resolve:
- Go to
- In Configuration Search, type HDFS Service Advanced Configuration Snippet (Safety Valve) for ranger-hdfs-security.xml .
- In HDFS Service Advanced Configuration Snippet (Safety Valve) for ranger-hdfs-security.xml, click + (Add).
- In Name, type ranger.optimize-subaccess-authorization.
- In Value, type true.
- Click Save Changes(CTRL+S).
Cluster cannot run jobs after Kerberos enabled
Symptom: Cluster previously configured without Kerberos authentication may fail to run jobs for certain users on certain TaskTrackers (MRv1) or NodeManagers (YARN) after enabling Kerberos for the cluster. Errors may display in the TaskTracker or NodeManager logs. The following example errors are from TaskTracker on MRv1:
10/11/03 01:29:55 INFO mapred.JobClient: Task Id : attempt_201011021321_0004_m_000011_0, Status : FAILED
Error initializing attempt_201011021321_0004_m_000011_0:
java.io.IOException: org.apache.hadoop.util.Shell$ExitCodeException:
at org.apache.hadoop.mapred.LinuxTaskController.runCommand(LinuxTaskController.java:212)
at org.apache.hadoop.mapred.LinuxTaskController.initializeUser(LinuxTaskController.java:442)
at org.apache.hadoop.mapreduce.server.tasktracker.Localizer.initializeUserDirs(Localizer.java:272)
at org.apache.hadoop.mapred.TaskTracker.localizeJob(TaskTracker.java:963)
at org.apache.hadoop.mapred.TaskTracker.startNewTask(TaskTracker.java:2209)
at org.apache.hadoop.mapred.TaskTracker$TaskLauncher.run(TaskTracker.java:2174)
Caused by: org.apache.hadoop.util.Shell$ExitCodeException:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:250)
at org.apache.hadoop.util.Shell.run(Shell.java:177)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:370)
at org.apache.hadoop.mapred.LinuxTaskController.runCommand(LinuxTaskController.java:203)
... 5 more- Cluster that had not been configured for Kerberos authentication was used to run jobs, which created local user directory (or directories) on each TaskTracker or NodeManager host.
- Cluster was then configured to use Kerberos authentication.
- Users try running jobs on the newly secured cluster but local user directories on TaskTrackers or NodeManagers are owned by the wrong user or have overly-permissive permissions.
Steps to resolve: Delete mapred.local.dir or
yarn.nodemanager.local-dirs directories across the cluster for affected
users.
NameNode fails to start
Caused by: KrbException: Integrity check on decrypted field failed (31) - PREAUTH_FAILED}}
Caused by: KrbException: Identifier does not match expected value (906)Possible cause: This issue may be due to incorrect configuration for AES-256. By
default, certain operating systems—CentOS/Red Hat Enterprise Linux 5.6 (and higher),
Ubuntu—use AES-256 encryption which requires installing the "Java Cryptography Extension
(JCE) Unlimited Strength Jurisdiction Policy File" on all hosts (see "JCE Policy File for
AES-256 Encryption" for details), or disabling AES-256 support in the
kdc.conf or krb5.com (see "Disable JCE Policy File for
AES-256 Encryption" for details).
Steps to resolve: KrbException 31 and KrbException 906 can be caused by various issues, but the most likely cause is incorrectly configured AES-256 encryption. Resolving the issue should start by determining the type of encryption configured for the cluster.
To verify the type of encryption configured for the cluster:
- On the local KDC host, type this command to create a test
principal:
kadmin -q "addprinc test" - On a cluster host, type this command to start a Kerberos session as
test:
kinit test - On a cluster host, type this command to view the encryption type in
use:
klist -eIf AES-256 is being used, output such as the following displays:
Ticket cache: FILE:/tmp/krb5cc_0 Default principal: test@SCM Valid starting Expires Service principal 05/19/11 13:25:04 05/20/11 13:25:04 krbtgt/SCM@SCM Etype (skey, tkt): AES-256 CTS mode with 96-bit SHA-1 HMAC, AES-256 CTS mode with 96-bit SHA-1 HMAC
To remove AES-256 encryption from the Kerberos configuration files:
- Remove
aes256-cts:normalfrom thesupported_enctypesfield of thekdc.conforkrb5.conffile. - After changing the configuration, restart the KDC and the kadmin servers.
- Change TGT principal (krbtgt/REALM@REALM) and other principal passwords as needed.
- In the [realms] section of the
kdc.conffile, for the realm associated withHADOOP.LOCALDOMAIN, add (or replace if it exists already) the following variable:supported_enctypes = des3-hmac-sha1:normal arcfour-hmac:normal des-hmac-sha1:normal des-cbc-md5:normal des-cbc-crc:normal des-cbc-crc:v4 des-cbc-crc:afs3 - Recreate the
hdfskeytab file andmapredkeytab file using the instructions in "Managing Kerberos credentials using Cloudera Manager".
Clients cannot connect to NameNode
Symptom: The NameNode keytab file does not have an AES-256 entry but the client tickets do. The NameNode starts but clients cannot connect to it. The error message does not specify "AES256" but rather contains enctype code "18."
Possible cause: Issue related to AES-256 encryption and the JCE library.
Steps to resolve: Verify that Java Cryptography Extension (JCE) Unlimited Strength
Jurisdiction Policy File is installed (see "JCE Policy File for AES-256 Encryption" for
instructions) or remove aes256-cts:normal from the
supported_enctypes field of the kdc.conf or
krb5.conf file, as detailed above.
Hadoop commands run in local realm but not in remote realm
Symptom: After enabling cross-realm trust, authenticating as a principal in the local realm lets you successfully run Hadoop commands, but authenticating as a principal in the remote realm does not.
Possible cause: This issue is often due to principals in the two realms having different encryption types or different passwords for the cross-realm principal in each realm. Because the local and remote realm each issue their own TGTs, the local commands run but the service ticket needed for the local and remote realms to communicate cannot be granted.
krbtgt principal and its
encryption types to the MIT KDC server using kadmin.local or
kadmin as appropriate (local access vs. remote):
kadmin: addprinc -e "enc_type_list" krbtgt/LOCAL-REALM.EXAMPLE.COM@MAIN-REALM.COMPANY.COMkrbtgt), for example, AES, DES, or RC4. Multiple encryption types can be
specified in the enc_type_list as long as one of the encryption types
matches that of the tickets granted by the KDC in the remote realm. For example:
kadmin: addprinc -e "aes256-cts:normal rc4-hmac:normal des3-hmac-sha1:normal" krbtgt/LOCAL-REALM.EXAMPLE.COM@MAIN-REALM.COMPANY.COMUsers cannot obtain credentials when running Hadoop jobs or commands
13/01/15 17:44:48 DEBUG ipc.Client: Exception encountered while connecting to the server : javax.security.sasl.SaslException:
GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Fail to create credential.
(63) - No service creds)]Possible cause: Ticket message may be too large for the UDP protocol (which is used by SASL by default).
libdefaults in the krb5.conf file on the
clients where the problem is occurring: [libdefaults]
udp_preference_limit = 1Configure krb5.conf through Cloudera Manager, this will automatically get added to
krb5.conf.
Unable to fetch new users/groups in Ranger after configuring usersync with LDAP using TLS
Symptom: After configuring usersync with LDAP using TLS, unable to fetch new users/groups in Ranger. The usersync logs show the following error:
2022-08-09 09:08:48,719 ERROR org.apache.ranger.ldapusersync.process.LdapUserGroupBuilder: LdapUserGroupBuilder.getGroups() failed with exception:
javax.naming.CommunicationException: simple bind failed: ldap.etrade.com:636
[Root exception is javax.net.ssl.SSLException: java.lang.RuntimeException:
Unexpected error: java.security.InvalidAlgorithmParameterException: the trustAnchors parameter must be non-empty]; remaining name 'ou=Group,dc=etrade,dc=com'- The truststore file does not exist, or is not configured. If is not set, the truststore will fall back into usersync's JAVA cacerts.
- The configured truststore does not have 'read' permissions for application user.
- Specify a valid path to a truststore file in JKS format.
- Provide read permissions to "others" at the OS level to the truststore. This way, the
"ranger" user will be able to read the truststore:
# cd <truststore location> # chmod 444 <truststore>
Usersync start fails with NullPointerException
Symptom: Usersync start fails with the following NullPointerException due to missing config properties.
2020-12-04 12:26:45,868 ERROR org.apache.ranger.authentication.UnixAuthenticationService: ERROR: Service: UnixAuthenticationService
java.lang.NullPointerException
at java.security.Provider$ServiceKey.<init>(Provider.java:872)
at java.security.Provider$ServiceKey.<init>(Provider.java:865)
at java.security.Provider.getService(Provider.java:1039)
at sun.security.jca.ProviderList.getService(ProviderList.java:332)
at sun.security.jca.GetInstance.getInstance(GetInstance.java:157)
at java.security.Security.getImpl(Security.java:695)
at java.security.KeyStore.getInstance(KeyStore.java:848)
at org.apache.ranger.authentication.UnixAuthenticationService.startService(UnixAuthenticationService.java:245)
at org.apache.ranger.authentication.UnixAuthenticationService.run(UnixAuthenticationService.java:122)
at org.apache.ranger.authentication.UnixAuthenticationService.main(UnixAuthenticationService.java:107)
2020-12-04 12:26:45,872 INFO org.apache.ranger.authentication.UnixAuthenticationService: Service: UnixAuthenticationService - STOPPED.Possible Cause:
This issue is caused due to missing keystore/ truststore type in user sync configs.
In CDP-7.1.5+ deployments, Ranger.truststore.file.type and ranger.keystore.file.type properties are set to jks by default. All prior versions do not have these properties defined in ranger-ugsync-site.xml. Due to CDPD-17769 (CLDR Internal), the default keystores/trust store file types are not used anymore, but taken from these properties.
Steps to Resolve: If you encounter this issue while starting or /restarting the usersync process, verify if the following properties exist in ranger-ugsync-site.xml and set these properties if missing.
Cloudera Clusters:
# grep -iE "ranger.truststore.file.type|ranger.keystore.file.type" /run/cloudera-scm-agent/process/*-ranger-RANGER_USERSYNC/conf/ranger-ugsync-site.xml -A1HDP Clusters:
# grep -iE "ranger.truststore.file.type|ranger.keystore.file.type" /etc/ranger/usersync/conf/ranger-ugsync-site.xml -A1To set the properties, do the following steps:
Cloudera Clusters:
- Go to
- Add the following properties:
- ranger.truststore.file.type=jks
- ranger.keystore.file.type=jks
HDP Clusters:
- Go to
- Add the following properties:
- ranger.truststore.file.type=jks
- ranger.keystore.file.type=jks
Bogus replay exceptions in service logs
Symptom: Multiple valid requests to Kerberos protected services are identified as replay attempts when they are not. The following exception shows up in the logs for one or more of the Hadoop daemons:
2013-02-28 22:49:03,152 INFO ipc.Server (Server.java:doRead(571)) - IPC Server listener on 8020: readAndProcess threw exception javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: Failure unspecified at GSS-API level (Mechanism l
javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: Failure unspecified at GSS-API level (Mechanism level: Request is a replay (34))]
at com.sun.security.sasl.gsskerb.GssKrb5Server.evaluateResponse(GssKrb5Server.java:159)
at org.apache.hadoop.ipc.Server$Connection.saslReadAndProcess(Server.java:1040)
at org.apache.hadoop.ipc.Server$Connection.readAndProcess(Server.java:1213)
at org.apache.hadoop.ipc.Server$Listener.doRead(Server.java:566)
at org.apache.hadoop.ipc.Server$Listener$Reader.run(Server.java:363)
Caused by: GSSException: Failure unspecified at GSS-API level (Mechanism level: Request is a replay (34))
at sun.security.jgss.krb5.Krb5Context.acceptSecContext(Krb5Context.java:741)
at sun.security.jgss.GSSContextImpl.acceptSecContext(GSSContextImpl.java:323)
at sun.security.jgss.GSSContextImpl.acceptSecContext(GSSContextImpl.java:267)
at com.sun.security.sasl.gsskerb.GssKrb5Server.evaluateResponse(GssKrb5Server.java:137)
... 4 more
Caused by: KrbException: Request is a replay (34)
at sun.security.krb5.KrbApReq.authenticate(KrbApReq.java:300)
at sun.security.krb5.KrbApReq.<init>(KrbApReq.java:134)
at sun.security.jgss.krb5.InitSecContextToken.<init>(InitSecContextToken.java:79)
at sun.security.jgss.krb5.Krb5Context.acceptSecContext(Krb5Context.java:724)
... 7 moreThis issue can also manifest as poor performance for clients of the cluster, including dropped connections, timeouts attempting to make RPC calls, and so on.
Possible cause: Kerberos uses a second-resolution timestamp to protect against replay attacks (where an attacker can record network traffic, and play back recorded requests later to gain elevated privileges). That is, incoming requests are cached by Kerberos for a little while, and if there are similar requests within a few seconds, Kerberos will be able to detect them as replay attack attempts (see "MIT Kerberos replay cache" for more information).
However, if there are multiple valid Kerberos requests coming in at the same time, these may also be misjudged as attacks for the following reasons:
- Multiple services in the cluster are using the same Kerberos principal. All
secure clients that run on multiple machines should use unique Kerberos principals for
each machine. For example, rather than connecting as a service principal
myservice@EXAMPLE.COM, services should have per-host principals such asmyservice/host123.example.com@EXAMPLE.COM. - Clocks not synchronized: All hosts should run NTP so that clocks are kept in sync between clients and servers.
Steps to resolve:
While having different principals for each service, and clocks in sync helps mitigate the
issue, there are, however, cases where even if all of the above are implemented, the problem
still persists. In such a case, disabling the cache (and the replay protection as a
consequence), will allow parallel requests to succeed. This compromise between
usability and security can be applied by setting the KRB5RCACHETYPE
environment variable to none.
Note that the KRB5RCACHETYPE is not automatically detected by Java
applications. For Java-based components:
- Ensure that the cluster runs on JDK 8.
- To disable the replay cache, add
-Dsun.security.krb5.rcache=noneto the Java Opts/Arguments of the targeted JVM. For example, HiveServer2 or the Sentry service.
Cloudera Manager cluster services fail to start
Exception in secureMain
java.lang.ExceptionInInitializerError
at javax.crypto.KeyGenerator.nextSpi(KeyGenerator.java:324)
at javax.crypto.KeyGenerator.<init>(KeyGenerator.java:157)
...
Caused by: java.lang.SecurityException: The jurisdiction policy files are not signed by a trusted signer!
at javax.crypto.JarVerifier.verifyPolicySigned(JarVerifier.java:289)
at javax.crypto.JceSecurity.loadPolicies(JceSecurity.java:316)
at javax.crypto.JceSecurity.setupJurisdictionPolicies(JceSecurity.java:261)
...Possible cause: This is another example of a mismatch for AES-256 encryption. Services cannot start when the version of the JCE policy file does not match the version of Java installed on a node because the cryptographic signatures for the JCE policy files cannot be verified, resulting in the message shown above.
- Check that the encryption types are matched between your KDC and
krb5.confon all hosts.Solution: If you are using AES-256, follow the instructions at "JCE Policy File for AES-256 Encryption" to deploy the JCE policy file on all hosts.
- Services cannot start
Download and unpack the zip file. Copy the two JAR files to the
$JAVA_HOME/jre/lib/security directory on each node within the cluster.
Error Messages
kafka-broker-ip-10-97-85-106.cloudera.site.log
2019-07-14 08:32:56,001 WARN org.apache.hadoop.security.ShellBasedUnixGroupsMapping: unable to return groups for user rangertagsync
PartialGroupNameException The user name 'rangertagsync' is not found. id: rangertagsync: no such user
id: rangertagsync: no such user
at org.apache.hadoop.security.ShellBasedUnixGroupsMapping.resolvePartialGroupNames(ShellBasedUnixGroupsMapping.java:294)
at org.apache.hadoop.security.ShellBasedUnixGroupsMapping.getUnixGroups(ShellBasedUnixGroupsMapping.java:207)
at org.apache.hadoop.security.ShellBasedUnixGroupsMapping.getGroups(ShellBasedUnixGroupsMapping.java:97)
at org.apache.hadoop.security.Groups$GroupCacheLoader.fetchGroupList(Groups.java:387)
at org.apache.hadoop.security.Groups$GroupCacheLoader.load(Groups.java:321)Possible Cause: User rangertagsync does not exist.
Steps to resolve: As an OS-level rangertagsync user is not required for any feature/functionality to work, manually adding an OS-level user = rangertagsync on all broker nodes seems to resolve the issue.
java.io.IOException: Incorrect permission for
/var/folders/B3/B3d2vCm4F+mmWzVPB89W6E+++TI/-Tmp-/tmpYTil84/dfs/data/data1,
expected: rwxr-xr-x, while actual: rwxrwxr-x
at org.apache.hadoop.util.DiskChecker.checkPermission(DiskChecker.java:107)
at org.apache.hadoop.util.DiskChecker.mkdirsWithExistsAndPermissionCheck(DiskChecker.java:144)
at org.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:160)
at org.apache.hadoop.hdfs.server.datanode.DataNode.makeInstance(DataNode.java:1484)
at org.apache.hadoop.hdfs.server.datanode.DataNode.instantiateDataNode(DataNode.java:1432)
at org.apache.hadoop.hdfs.server.datanode.DataNode.instantiateDataNode(DataNode.java:1408)
at org.apache.hadoop.hdfs.MiniDFSCluster.startDataNodes(MiniDFSCluster.java:418)
...Possible cause: The daemon has umask 0002 rather than 0022.
Steps to resolve: Make sure that the umask for
hdfs and mapred is 0022.
These error messages are associated with MapReduce only (not YARN).
WARN org.apache.hadoop.mapred.TaskTracker: Exception while localization java.io.IOException: Job initialization failed (1) Possible cause:
- Add the
mapreduser to themapredandhadoopgroups on all hosts. - Restart all TaskTrackers.
Jobs cannot run and TaskTracker cannot create local mapred directory
11/08/17 14:44:06 INFO mapred.TaskController: main : user is atm
11/08/17 14:44:06 INFO mapred.TaskController: Failed to create directory /var/log/hadoop/cache/mapred/mapred/local1/taskTracker/atm - No such file or directory
11/08/17 14:44:06 WARN mapred.TaskTracker: Exception while localization java.io.IOException: Job initialization failed (20)
at org.apache.hadoop.mapred.LinuxTaskController.initializeJob(LinuxTaskController.java:191)
at org.apache.hadoop.mapred.TaskTracker$4.run(TaskTracker.java:1199)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:396)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1127)
at org.apache.hadoop.mapred.TaskTracker.initializeJob(TaskTracker.java:1174)
at org.apache.hadoop.mapred.TaskTracker.localizeJob(TaskTracker.java:1089)
at org.apache.hadoop.mapred.TaskTracker.startNewTask(TaskTracker.java:2257)
at org.apache.hadoop.mapred.TaskTracker$TaskLauncher.run(TaskTracker.java:2221)
Caused by: org.apache.hadoop.util.Shell$ExitCodeException:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:255)
at org.apache.hadoop.util.Shell.run(Shell.java:182)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:375)
at org.apache.hadoop.mapred.LinuxTaskController.initializeJob(LinuxTaskController.java:184)
... 8 morePossible cause: Mismatch of mapred.local.dir values specified in
mapred-site.xml and taskcontroller.cfg. These values
should be the same.
Steps to resolve: Verify that the setting for mapred.local.dir is
the same in both mapred-site.xml and taskcontroller.cfg,
and reconfigure if necessary.
11/08/17 14:48:23 INFO mapred.TaskController: Failed to create directory /home/atm/src/cloudera/hadoop/build/hadoop-0.23.2-cdh3u1-SNAPSHOT/logs1/userlogs/job_201108171441_0004 - No such file or directory
11/08/17 14:48:23 WARN mapred.TaskTracker: Exception while localization java.io.IOException: Job initialization failed (255)
at org.apache.hadoop.mapred.LinuxTaskController.initializeJob(LinuxTaskController.java:191)
at org.apache.hadoop.mapred.TaskTracker$4.run(TaskTracker.java:1199)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:396)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1127)
at org.apache.hadoop.mapred.TaskTracker.initializeJob(TaskTracker.java:1174)
at org.apache.hadoop.mapred.TaskTracker.localizeJob(TaskTracker.java:1089)
at org.apache.hadoop.mapred.TaskTracker.startNewTask(TaskTracker.java:2257)
at org.apache.hadoop.mapred.TaskTracker$TaskLauncher.run(TaskTracker.java:2221)
Caused by: org.apache.hadoop.util.Shell$ExitCodeException:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:255)
at org.apache.hadoop.util.Shell.run(Shell.java:182)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:375)
at org.apache.hadoop.mapred.LinuxTaskController.initializeJob(LinuxTaskController.java:184)
... 8 morePossible cause: Misconfiguration issue.
Steps to resolve: In MRv1, the default value specified for
hadoop.log.dir in mapred-site.xml is
/var/log/hadoop-0.20-mapreduce. The path must be owned and be writable
by the mapred user. If you change the default value specified for
hadoop.log.dir, make sure the value is identical in
mapred-site.xml and taskcontroller.cfg. If the values
are different, the error message above is returned.
User not allowed to impersonate rangeradmin when viewing KMS encryption keys
[...]org.apache.ranger.plugin.client.HadoopException: { "RemoteException" : { "message" : "User: rangeradmin/host.example.com@EXAMPLE.COM is not allowed to impersonate rangeradmin", "exception" : "AuthorizationException", "javaClassName" : "org.apache.hadoop.security.authorize.AuthorizationException" } }Possible cause:
Steps to resolve:
- Go to
- In Configuration Search, type Ranger KMS Server with KTS Advanced Configuration Snippet (Safety Valve) for conf/kms-site.xml.
- In Ranger KMS Server with KTS Advanced Configuration Snippet (Safety Valve) for conf/kms-site.xml, click + (Add).
- In Name, type hadoop.kms.proxyuser.rangeradmin.hosts.
- In Value, type *.
- Click + (Add).
- In Name, type hadoop.kms.proxyuser.rangeradmin.groups.
- In Value, type *.
- Click Save Changes(CTRL+S).
- Restart Ranger service.