Environment health checks
You can use environment health checks to verify the health of various ECS components. If you are experiencing issues, these tests can help you diagnose and solve the problem.
Host health checks
Check the status of all nodes in the Kubernetes environment
[root@test-1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
test-1.vpc.cloudera.com Ready control-plane,etcd,master 2d4h v1.25.14+rke2r1
test-2.vpc.cloudera.com Ready <none> 2d4h v1.25.14+rke2r1Ensure that the namespaces are all active
[root@test-1 ~]# kubectl get namespaces
NAME STATUS AGE
cdp Active 2d4h
cdp-drs Active 2d4h
cdp-services Active 2d4h
default Active 2d4h
ecs-webhooks Active 2d4h
infra-prometheus Active 2d4h
k8tz Active 2d4h
kube-node-lease Active 2d4h
kube-public Active 2d4h
kube-system Active 2d4h
kubernetes-dashboard Active 2d4h
liftie-wjtncjzm-ns Active 2d4h
local-path-storage Active 2d4h
longhorn-system Active 2d4h
observability Active 2d4h
pod-reaper Active 2d4h
test-1-5ea742bf-monitoring-platform Active 2d4h
vault-system Active 2d4h
yunikorn Active 2d4hVault health checks
Vault states
There are three possible states the Vault can be in:
-
Initialization:
This involves preparing the Vault's storage back end to accept data. This cannot be executed on a Vault cluster that has already been initialized. The Vault operates with a self-signed certificate, and the
ecs_util.shscript encompasses all of the necessary steps for this process. -
Unsealing:
If the Vault is resealed, restarted, or stopped, a minimum of three keys are required to unseal it to resume request handling. The Vault does not retain the generated root key, as the root key must be reconstructed using at least three keys, or the vault remains permanently sealed. Cloudera stores the root key in Cloudera Manager, and this is the key that is used when the unseal option is selected from the Cloudera Manager user interface.
-
Startup:
After completing initialization and unsealing, the Vault is ready to be started. Once operational, it can begin processing requests.
Check the Vault status
[root@test-1 ~]# kubectl get pods -n vault-system
NAME READY STATUS RESTARTS AGE
helm-install-vault-pd842 0/1 Completed 0 2d6h
vault-0 1/1 Running 0 2d6h
vault-exporter-84bd8f848d-s9grm 1/1 Running 0 2d6hUnseal the Vault using Cloudera Manager
You should only unseal the Vault if there are issues reported in the logs about the Vault being sealed, or if pods in the Vault namespace are crash-looping.
To unseal the Vault, select the ECS cluster in Cloudera Manager, click ECS, then select Actions > Unseal Vault.
Storage health checks
Check storage mounts
[cloudera@fluentd-aggregator-0 /]$ mount | grep longhorn
/dev/longhorn/pvc-2f71ea50-744c-4eb9-875c-3f793d141961 on /var/log type ext4 (rw,relatime,data=ordered)Check Longhorn status
[root@test-1 ~]# kubectl get pods -n longhorn-system
NAME READY STATUS RESTARTS AGE
csi-attacher-7b556d5f87-2rttk 1/1 Running 0 2d10h
csi-attacher-7b556d5f87-ldst4 1/1 Running 0 2d10h
csi-attacher-7b556d5f87-nsrnn 1/1 Running 0 2d10h
csi-provisioner-76f6697668-567c5 1/1 Running 0 2d10h
csi-provisioner-76f6697668-6smx5 1/1 Running 0 2d10h
csi-provisioner-76f6697668-w82z5 1/1 Running 0 2d10h
csi-resizer-5d8b75df89-gn7jk 1/1 Running 0 2d10h
csi-resizer-5d8b75df89-m2r87 1/1 Running 0 2d10h
csi-resizer-5d8b75df89-zthrl 1/1 Running 0 2d10h
csi-snapshotter-c54d8cbd8-2vmxs 1/1 Running 0 2d10h
csi-snapshotter-c54d8cbd8-52sjc 1/1 Running 0 2d10h
csi-snapshotter-c54d8cbd8-f49gj 1/1 Running 0 2d10h
engine-image-ei-791d1d81-7bv7b 1/1 Running 0 2d10h
engine-image-ei-791d1d81-zb2kv 1/1 Running 0 2d10h
helm-install-longhorn-zchvx 0/1 Completed 0 2d10h
instance-manager-e-050ae22aa5b0f98c28dc7da17d4e6ba2 1/1 Running 0 2d10h
instance-manager-e-5830ecda079889e4a49271591835ceb2 1/1 Running 0 2d10h
instance-manager-r-050ae22aa5b0f98c28dc7da17d4e6ba2 1/1 Running 0 2d10h
instance-manager-r-5830ecda079889e4a49271591835ceb2 1/1 Running 0 2d10h
longhorn-admission-webhook-6cb4bb94f-2252d 1/1 Running 0 2d10h
longhorn-admission-webhook-6cb4bb94f-hfqvz 1/1 Running 0 2d10h
longhorn-conversion-webhook-76fd55b9-rklhz 1/1 Running 0 2d10h
longhorn-conversion-webhook-76fd55b9-sxkkb 1/1 Running 0 2d10h
longhorn-csi-plugin-czjtm 3/3 Running 0 2d10h
longhorn-csi-plugin-f26j7 3/3 Running 0 2d10h
longhorn-driver-deployer-7b64685666-7nx6v 1/1 Running 0 2d10h
longhorn-manager-tjz5h 1/1 Running 0 2d10h
longhorn-manager-x9r26 1/1 Running 0 2d10h
longhorn-recovery-backend-fc6dccdcb-vnqb6 1/1 Running 0 2d10h
longhorn-recovery-backend-fc6dccdcb-w4fdr 1/1 Running 0 2d10h
longhorn-ui-79c96b46cb-4jqrq 1/1 Running 0 2d10h
longhorn-ui-79c96b46cb-fvn5g 1/1 Running 0 2d10hCheck Longhorn status using the UI
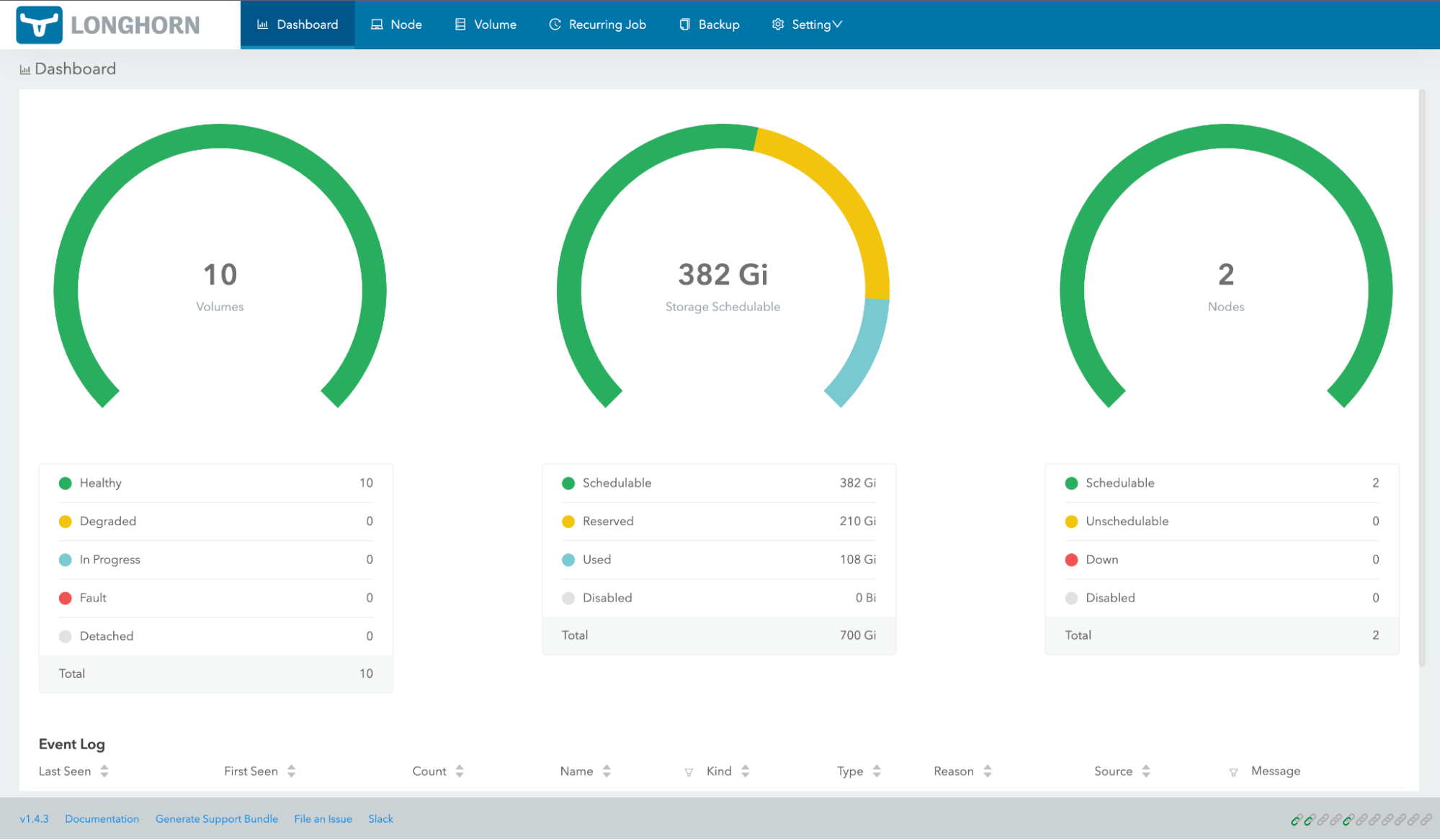
In Cloudera Manager, click ECS, then select Web UI > Storage UI.

A healthy system should show healthy volumes, schedulable storage, and schedulable nodes:
Persistent volume claims
Use the following command format to list the persistent volume claims in a namespace:
kubectl get pvc -n <namespace>For example, to list the persistent volume claims in the cdp namespace:

Common storage issues and workarounds
longhorn-manager not present
Check to see if the longhorn-manager daemonset exists in the
longhorn-system namespace. If not, it may have been accidentally deleted. To
restore it via the Helm chart:
export KUBECONFIG=/etc/rancher/rke2/rke2.yaml
cd /opt/cloudera/parcels/ECS/installer/install/bin/linux
./helm history longhorn -n longhorn-system (note down the latest revision)
./helm rollback longhorn <revision> -n longhorn-systemVolume fails to attach to node
When this issue occurs, Longhorn manager reports the following error:
time="2023-03-03T01:42:30Z" level=warning
msg="pvc-e930fca4-0c90-44b0-bedb-9d9d39ec197c-e-c87678d7: 2023/03/02 09:27:40
cannot create an available backend for the engine from the addresses
[tcp://10.42.0.21:10120]"Checking the instance-manager pod logs, it shows a discrepancy between the actual and the expected volume size. The volume size has drifted from the requested pvc:
[pvc-e930fca4-0c90-44b0-bedb-9d9d39ec197c-r-57d7d0e6]
time="2023-03-03T01:48:08Z" level=info msg="Opening volume
/host/ecs/longhorn-storage/replicas/pvc-e930fca4-0c90-44b0-bedb-9d9d39ec197c-fb
bf1fa2, size 10737418240/512"
2023-01-30T14:59:53.514816555-08:00 stderr F
[pvc-84f1c799-284c-4676-9c3a-34a7fdcfe8cc-e-3b7dabc9]
time="2023-01-30T22:59:53Z" level=warning msg="backend tcp://10.42.1.47:10000
size does not match 2147483648 != 64424509440 in the engine initiation phase"This can be resolved by updating the volume size to the original expected size:
-
SSH into the node that has the replica.
-
cdinto the replica folder, for example:cd /longhorn/replicas/pvc-126d40e2-7bff-4679-a310-1a5dc941 -
Change the
sizefield from its current value to the expected value in thevolume.metafile.