You need to scan the CDH or Cloudera Base on premises
source cluster to identify the available datasets and workloads that can be migrated.
Scanning also enables you to review and resolve syntax errors that can occur after the
migration.
Click on the CDH or Cloudera Base on premises
cluster you want to use for the migration on the Clusters
page.
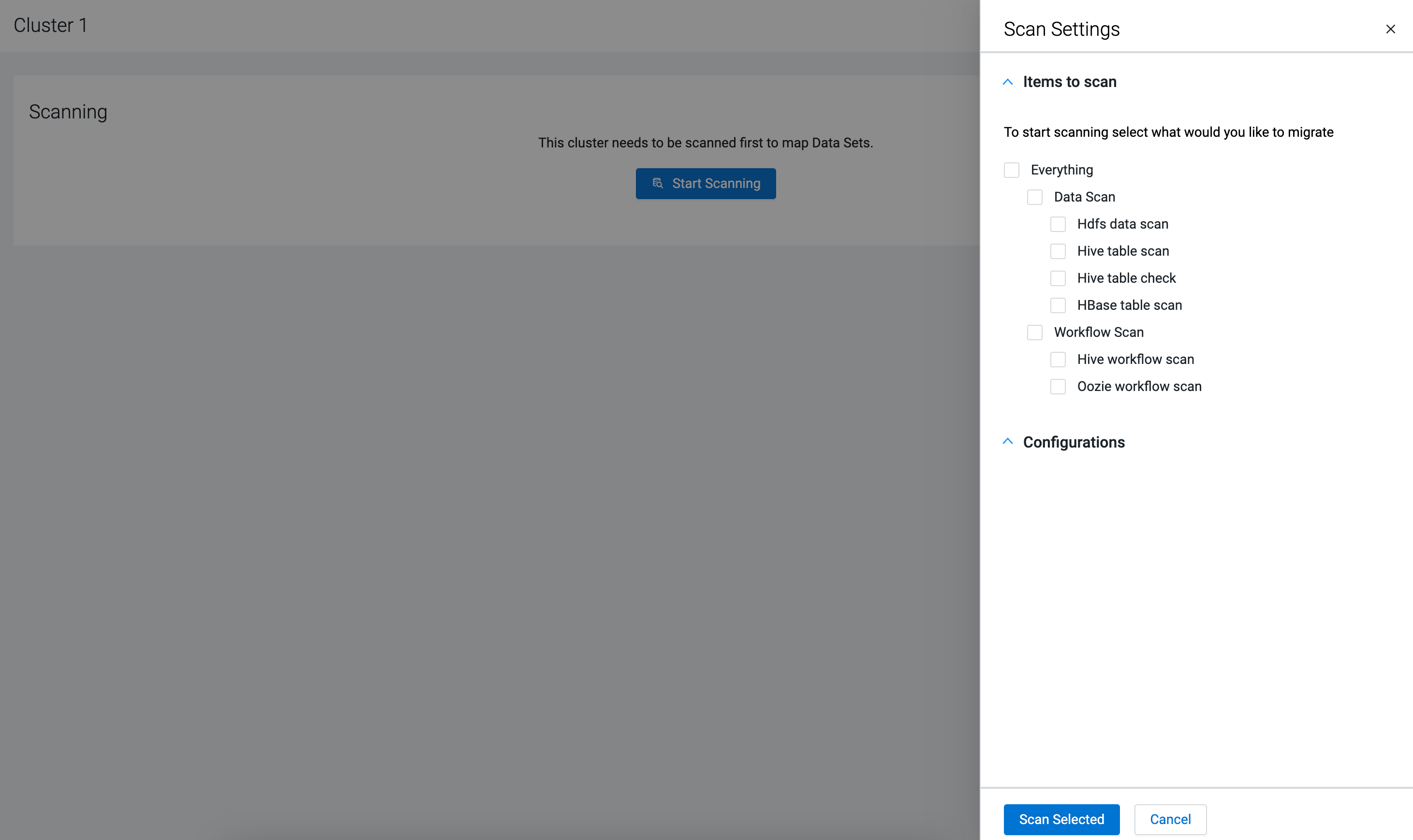
Click Start Scanning to open the Scan
Settings where you can select the data and workloads for
scanning.
Select Everything or choose from the different scanning
options.
The following items are available for scanning:
HDFS data scan
The HDFS data scan uses _hdfs_report_ module from
the CDH Discovery Tool to scan HDFS on the source
cluster.
Hive table scan
The Hive table scan uses _hive_metastore_ module
from the CDH Discovery Tool to scan Hive on the source
cluster.
Hive table check
Scanning Hive tables on the source cluster. _Hive Table
Check_ embeds sre and
u3 sub-programs of the Hive SRE
Tooling. The result will be visible at the SRE column of
the Hive datasets.
HBase table scan
Scanning HBase tables on the source cluster.
Hive workflow scan
Scanning Hive SQL queries on the source cluster. You can pre-scan
Hive2 SQL queries against Hive3 with the Hive Workflow scan option.
When selecting this Hive Workflow option, you need to provide the
location of your queries as shown in the following example:
HDFS paths
With default namespace:
hdfs:///dir/,
hdfs:///dir/file
With specified namespace:
hdfs://namespace1/dir,
hdfs://namespace1/dir/file
With namenode address:
hdfs://nameNodeHost:port:/dir,
hdfs://nameNodeHost:port:/dir/file
Native file paths
your/local/dir
nodeFQDN:/your/local/dir/sqlFile
Oozie workflow scan
Scanning Oozie workloads on the source cluster. If you selected
Oozie workflow scan, you need to provide the Number of
latest days to scan.
Spark application scan
Scanning Spark applications on the source cluster. If you
selected Spark application scan, you need to provide the
Number of latest days to
scan.
Spark History Server needs to be configured to be accessible
by the spark user, to do that you can add
spark to the list in
spark.history.ui.admin.acls at the
SPARK_ON_YARN service in Cloudera Manager.
Spark jobs also need to be visible by the the user
spark.
Click Scan selected.
You will be redirected to the scanning progress where you can monitor if the
selected items are successfully scanned or encountered an error.
Click Scan
Cluster to open the Scan Settings
again to add more items to the scan or trigger a rescan of the already
scanned items.
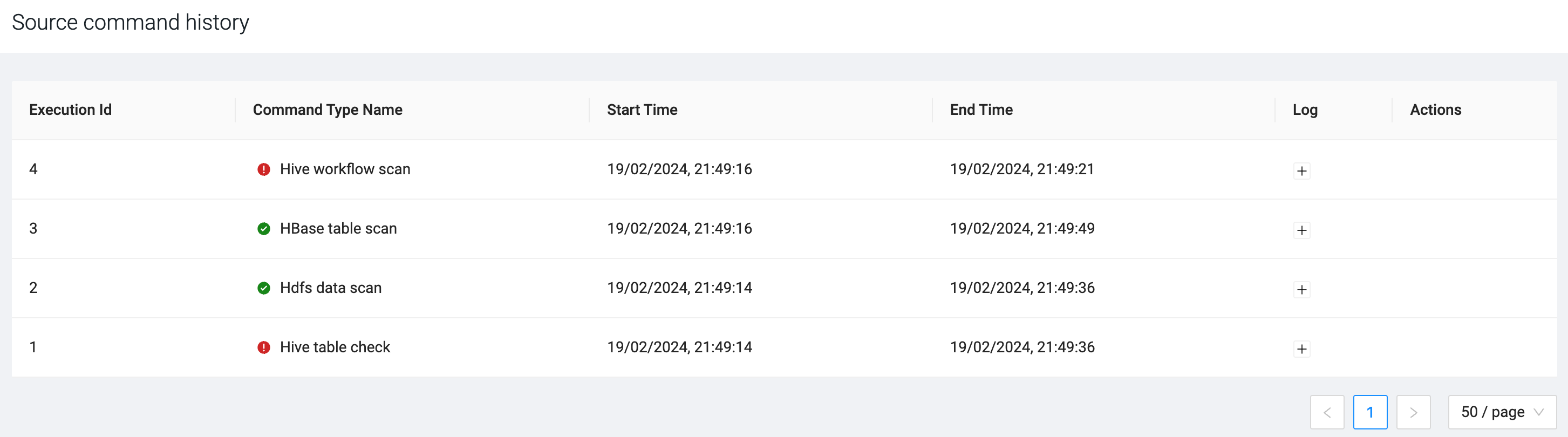
Click Command
Historz to open the Source command
history to have more insight about the scanning progress,
stop an in progress scan and review the log.
Click Start Mapping to review the data, workflows and
applications on the source cluster and map their configuration to the
destination cluster.
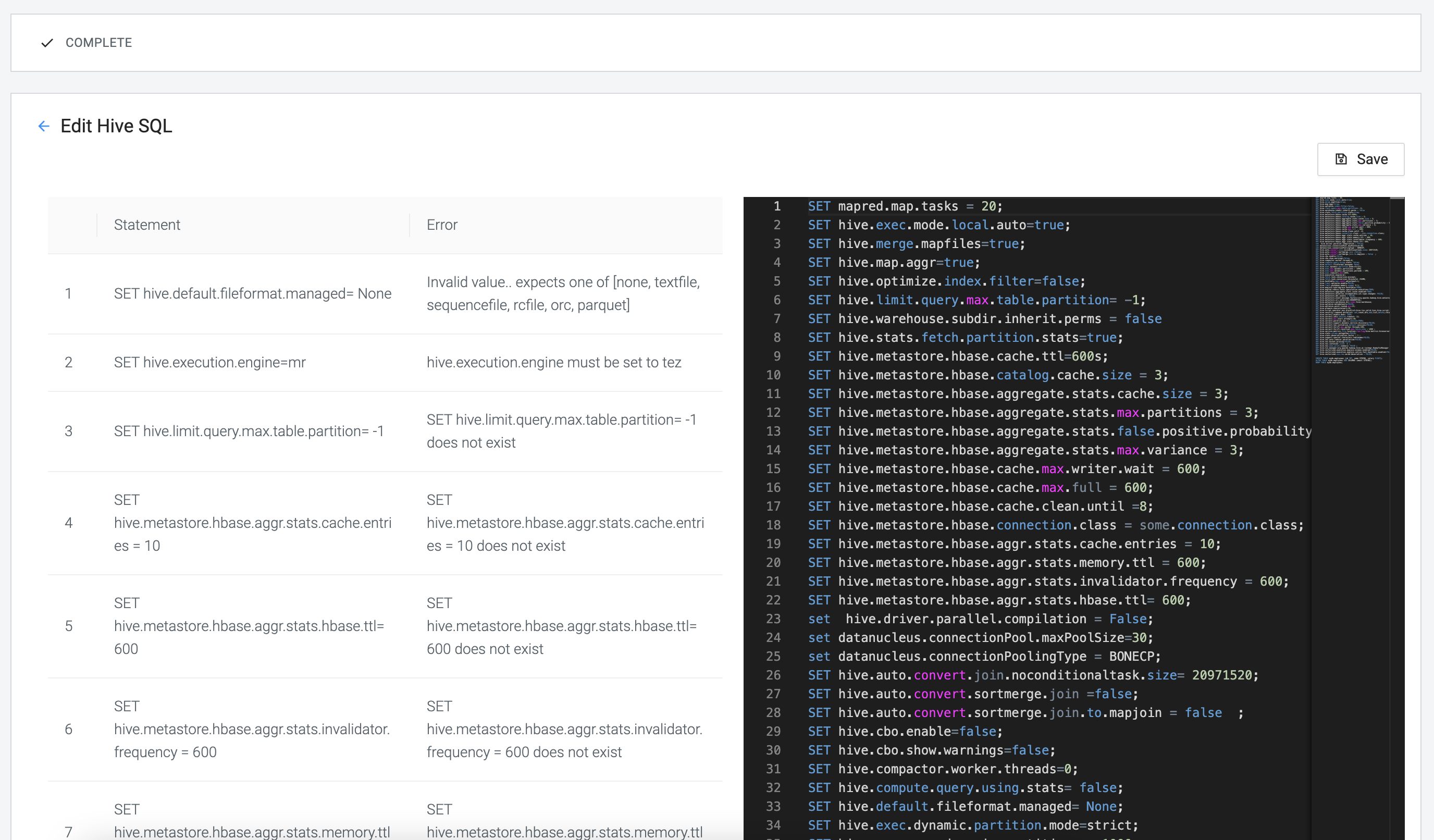
For example, when reviewing Hive SQL, you can check and
edit any SQL query related errors before migrating the workflows to Clouderaon cloud. The migration will be successful
regardless of fixing the statement errors. However, you will not be able to
execute the SQL queries on the new cluster due to the compatibility issues
between Hive2 and Hive3. You can review the list of errors using , and open the editor using .After fixing the statement errors in the SQL editor window,
Save the changes. The edited queries are replicated
and saved in the S3 bucket of the destination cluster. The original files are
not overwritten.
After the scanning is completed, you can add the tables and workflows from the
selected services to collections. Collections serve as an
organizational method to sort out the data and workflows resulted from the scan
for migration.
The datasets and workflow on the CDH or Cloudera Base on premises source cluster is scanned for
Hive, HDFS, HBase, Oozie and Spark.Sort the scanned data and workflows into collections to have more control over what
is migrated from the source cluster to the target cluster.

 Scan
Cluster to open the Scan Settings
again to add more items to the scan or trigger a rescan of the already
scanned items.
Scan
Cluster to open the Scan Settings
again to add more items to the scan or trigger a rescan of the already
scanned items.
 Command
Historz to open the Source command
history to have more insight about the scanning progress,
stop an in progress scan and review the log.
Command
Historz to open the Source command
history to have more insight about the scanning progress,
stop an in progress scan and review the log.
 , and open the editor using
, and open the editor using  .
. After the scanning is completed, you can add the tables and workflows from the selected services to collections. Collections serve as an organizational method to sort out the data and workflows resulted from the scan for migration.
After the scanning is completed, you can add the tables and workflows from the selected services to collections. Collections serve as an organizational method to sort out the data and workflows resulted from the scan for migration.