CDS 2.x Powered by Apache Spark
Apache Spark is a general purpose framework for distributed computing that offers high performance for both batch and stream processing. It exposes APIs for Java, Python, R, and Scala, as well as an interactive shell for you to run jobs.
Cloudera Data Science Workbench provides interactive and batch access to Spark 2. Connections are fully secure without additional configuration, with each user accessing Spark using their Kerberos principal. With a few extra lines of code, you can do anything in Cloudera Data Science Workbench that you might do in the Spark shell, as well as leverage all the benefits of the workbench. Your Spark applications will run in an isolated project workspace.
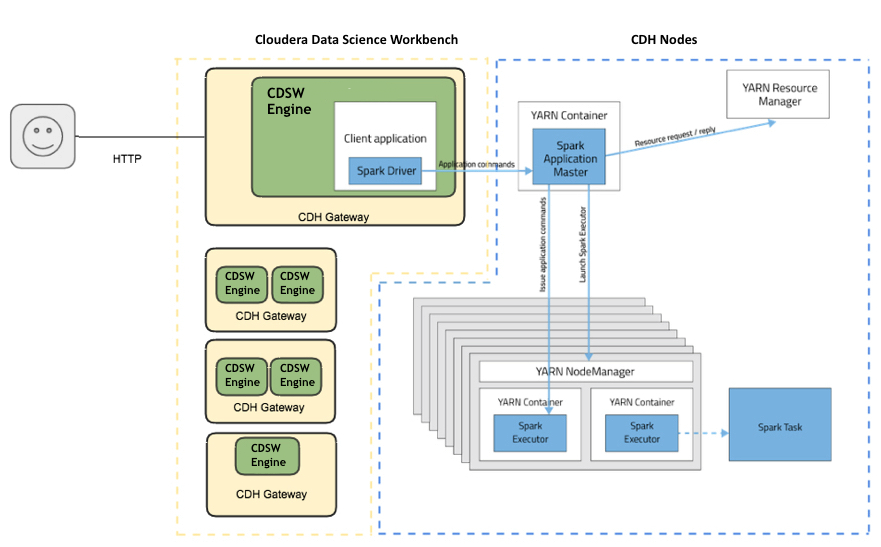
Cloudera Data Science Workbench's interactive mode allows you
to launch a Spark application and work iteratively in R, Python, or
Scala, rather than the standard workflow of launching an application
and waiting for it to complete to view the results. Because of its
interactive nature, Cloudera Data Science Workbench works with Spark
on YARN's client mode, where the driver persists
through the lifetime of the job and runs executors with full access to
the CDH cluster resources. This architecture is illustrated the
following figure: