Configuring the Engine Environment
This section describes some of the ways you can configure engine environments to meet the requirements of your projects.
- Environmental Variables
- For information on how environmental variables can be used to configure engine environments in Cloudera Data Science Workbench, see https://docs.cloudera.com/cdsw/1.10.2/environment-variables/topics/cdsw-environment-variables.html.
- CDH Parcel Directory
- Starting with Cloudera Data Science Workbench 1.5, the CDH parcel directory property is no longer available in the Site
Administration panel. By default, Cloudera Data Science Workbench looks for the CDH
parcel at
/opt/cloudera/parcels.If you want to use a custom location for your parcels, use one of the following methods to configure this custom location:
CSD deployments: If you are using the default parcel directory,
/opt/cloudera/parcels, no action is required. If you want to use a custom location for the parcel directory, configure this in Cloudera Manager as documented here.OR
RPM deployments: If you are using the default parcel directory,
/opt/cloudera/parcels, no action is required. If you want to specify a custom location for the parcel directory, configure theDISTRO_DIRproperty in thecdsw.conffile on both master and worker hosts. Runcdsw restartafter you make this change. - Configuring Host Mounts
- By default, Cloudera Data Science Workbench will automatically mount the CDH parcel
directory and client configuration for required services such as HDFS, Spark, and
YARN into each project's engine. However, if users want to reference any additional
files/folders on the host, site administrators will need to configure them here so
that they are loaded into engine containers at runtime. Note that the directories
specified here will be available to all projects across the deployment.
To configure additional mounts, go to and add the paths to be mounted from the host to the Mounts section.
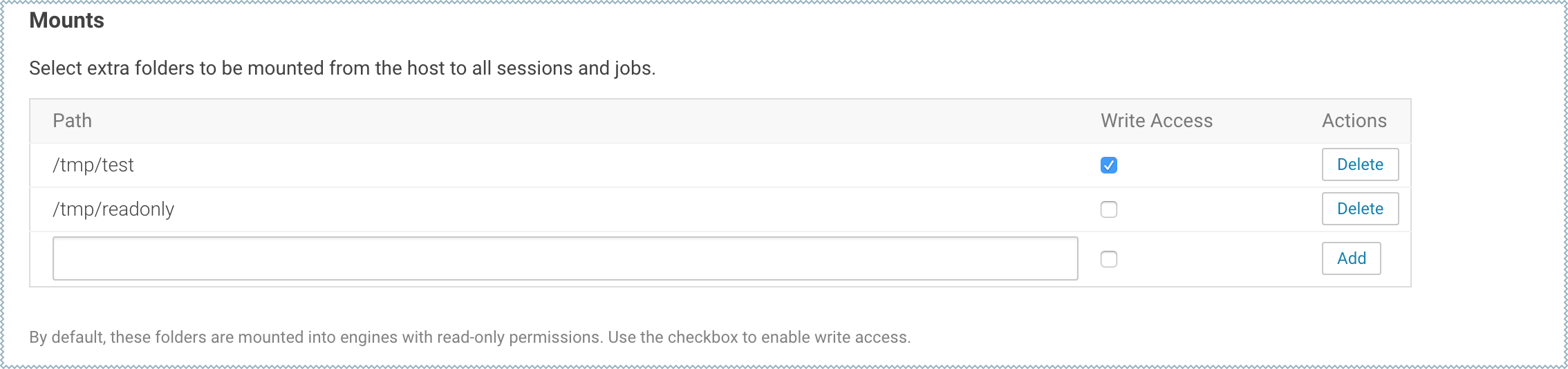 The following table summarizes how mounts are loaded into engine containers in current and previous Cloudera Data Science Workbench releases.
The following table summarizes how mounts are loaded into engine containers in current and previous Cloudera Data Science Workbench releases.CDSW Version Mount Point Permissions in Engines 1.4.2 (and higher) By default, mount points are loaded into engine containers with read-only permissions. CDSW 1.4.2 (and higher) also include a Write Access checkbox (see image) that you can use to enable read-write access for individual mounted directories. Note that these permissions will apply to all projects across the deployment.
1.4.0 Mount points are loaded into engine containers with read-only permissions.
1.3.x (and lower) Mount points are loaded into engine containers with read-write permissions.
Points to Remember:-
When adding host mounts, try to be as generic as possible without mounting common system files. For example, if you want to add several files under
/etc/spark2-conf, you can simplify and mount the/etc/spark2-confdirectory; but adding the parent/etcmight prevent the engine from running.As a general rule, do not mount full system directories that are already in use; such as
/var,/tmp, or/etc. This also serves to avoid accidentally exposing confidential information in running sessions. Do not setJAVA_HOMEto a path under these directories because CDSW sessions will mount theJAVA_HOMElocation from the host in the session engine container which can interfere with the operation of the engine container. -
Do not add duplicate mount points. This will lead to sessions crashing in the workbench.
-
- Configuring Shared Memory Limit for Docker Images
- You can increase the shared memory size for the sessions, experiments, and jobs
running within an Engine container within your project. For Docker, the default size
of the available shared memory is 64MB.To increase the shared memory limit:
- From CDSW web UI, go to .
- Specify the shared memory size in the Shared Memory Limit field.
- Click Save Advanced Settings to save the configuration and exit.
This mounts a volume with the
tmpfsfile system to/dev/shmand Kubernetes will enforce the given limit. The maximum size of this volume is the half of your physical RAM in the node without the swap. - Setting Time Zones for Sessions and Jobs
- The default time zone for Cloudera Data Science Workbench sessions is UTC. This is
the default regardless of the time zone setting on the Master host.
To change to your preferred time zone, for example, Pacific Standard Time (PST), navigate to . Under the Environmental Variables section, add a new variable with the name set to
TZand value set toAmerica/Los_Angeles, and click Add.