Security Model
Cloudera Data Science Workbench uses Kubernetes to schedule and manage Docker containers.
All Cloudera Data Science Workbench components (web application, PostgreSQL database, Livelog, and so on) run inside Docker containers. These are represented on the left-hand side of the diagram. Similarly, the environments that users operate in (via sessions, jobs, experiments, models), also run within isolated Docker containers that we call engines.
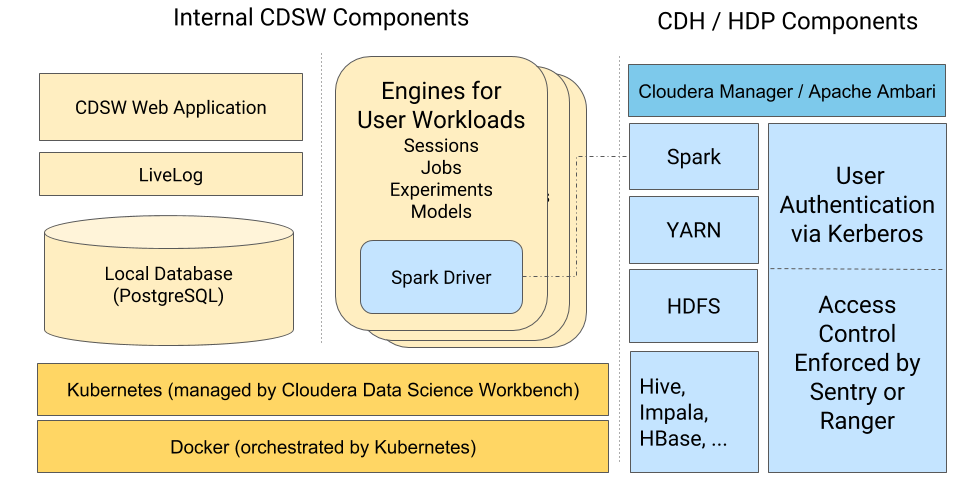
This architecture allows Cloudera Data Science Workbench to leverage the isolation properties of Docker to achieve notable security benefits.
-
Isolated File System: The Docker container does not see the host file system, but instead sees only the filesystem provided by the container and any host volumes that you have explicitly mounted into the container. This means a user launching a Cloudera Data Science Workbench session will only have access to the project files, and any specific host volumes you have chosen to mount into the session engine. They will not otherwise have access to the underlying host filesystem.
-
Isolated Process Namespace: Docker containers cannot affect any processes running either on the host operating system or in other containers. Cloudera Data Science Workbench creates a new container each time a session/job/experiment/model is launched. This means user workloads can run in complete isolation from each other.
For more details on the Docker security model, see Docker Security Overview.