Monitoring Individual Models
When a model is deployed, Cloudera Data Science Workbench allows you to specify a number of replicas that will be deployed to serve requests.
Having more replicas means that your model should be able to serve more requests and is more resilient. However, we should not expect the distribution of requests to models to be completely evenly distributed across replicas. For instance, if you have one request that takes thirty seconds and two more immediate requests that take five seconds, we would expect the second replica to process more of the requests.
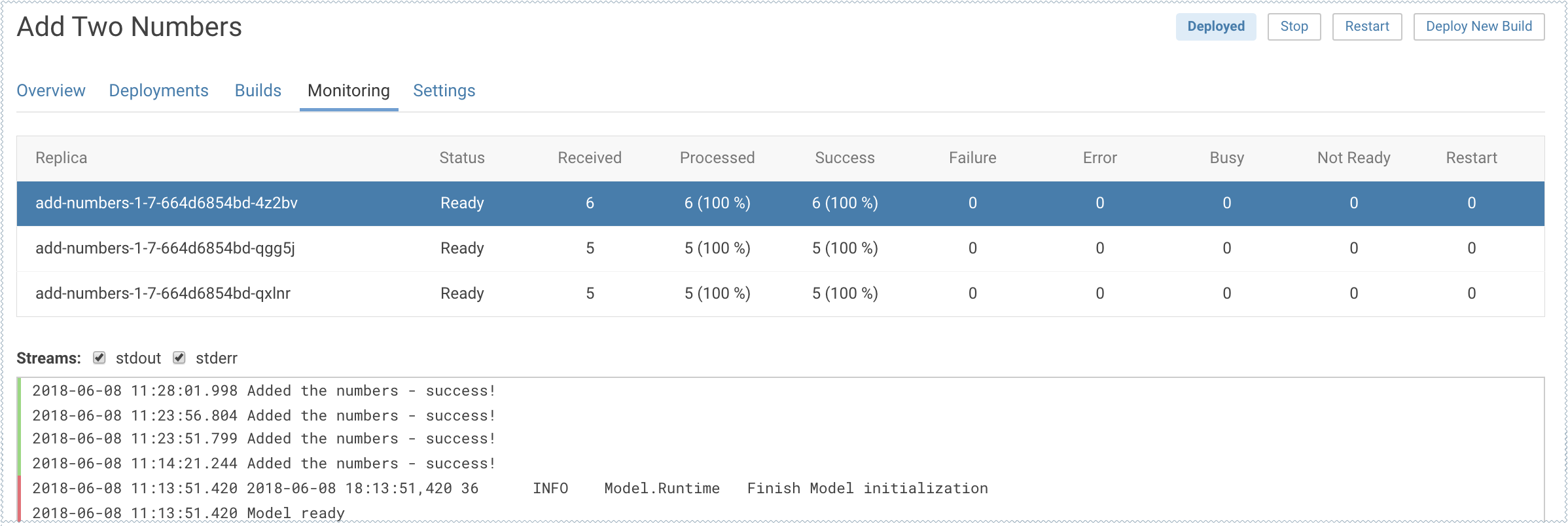
For each active model, you can monitor its replicas by going to the
model's Monitoring page. On this
page you can track the number of requests being served by each replica, success and failure
rates, and their associated stderr and
stdout logs. Depending on future resource
requirements, you can increase or decrease the number of replicas by re-deploying the
model.
The most recent logs are at the top of the pane (see image). stderr logs are displayed next to a red bar while
stdout logs are by a green bar. Note that
model logs and statistics are only preserved so long as the individual replica is active. When
a replica restarts (for example, in case of bad input) the logs also start with a clean slate.