Add the Cloudera Data Science Workbench Service
Perform the following steps to add the Cloudera Data Science Workbench service to your cluster.
- On the
tab, click
 to the right of the cluster
name and select Add a Service to launch the wizard. A list of
services will be displayed.
to the right of the cluster
name and select Add a Service to launch the wizard. A list of
services will be displayed. -
Assign the CDSW roles, HDFS, Spark 2, and YARN, to gateway hosts:
- Master
- Assign the Master role to a gateway host that is the designated Master host. This is the host that should have the Application Block Device mounted to it.
- Worker
-
Assign the Worker role to any other gateway hosts that will be used for Cloudera Data Science Workbench. Note that Worker hosts are not required for a fully-functional Cloudera Data Science Workbench deployment. For proof-of-concept deployments, you can deploy a 1-host cluster with just a Master host. The Master host can run user workloads just as a worker host can.
Even if you are setting up a multi-host deployment, do not assign the Master and Worker roles to the same host . By default, the Master host doubles up to perform both functions: those of the Master and those of a worker.
- Docker Daemon
-
This role runs underlying Docker processes on all Cloudera Data Science Workbench hosts. The Docker Daemon role must be assigned to every Cloudera Data Science Workbench gateway host.
On First Run, Cloudera Manager will automatically assign this role to each Cloudera Data Science Workbench gateway host. However, if any more hosts are added or reassigned to Cloudera Data Science Workbench, you must explicitly assign the Docker Daemon role to them.
- Application
-
This role runs the Cloudera Data Science Workbench application. This role runs only on the CDSW Master host.
On First Run, Cloudera Manager will assign the Application role to the host running the Cloudera Data Science Workbench Master role. The Application role is always assigned to the same host as the Master. Consequently, this role must never be assigned to a Worker host.
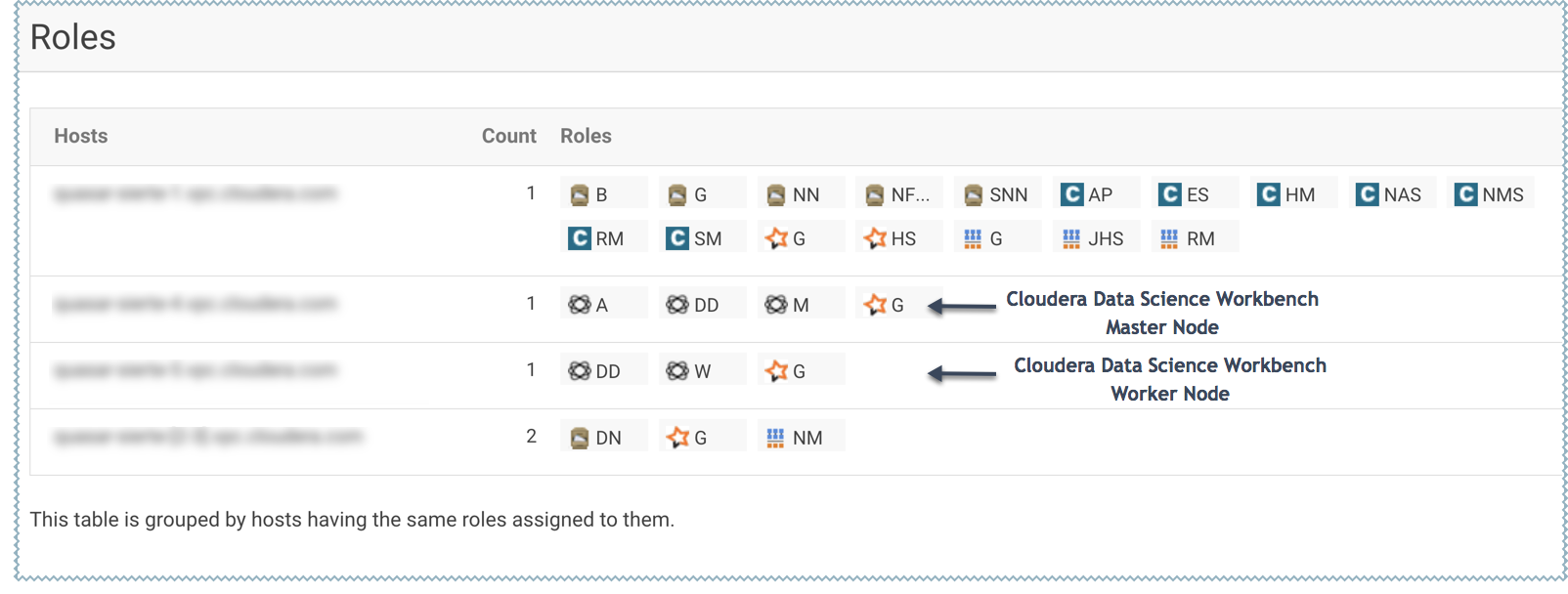
The following image shows the role assignments for a Cloudera Data Science Workbench Master host and Worker host: