Using DefragmentText processor
Learn about the DefragmentText processor, its properties, its relationships, and its limitations. Also learn about how to use the DefragmentText processor.
DefragmentText processor buffers the incoming flow files until their contents create a cohesive message, based on the start or end line pattern.
Properties
- Pattern
A regular expression to match at the start or end of messages.
- Pattern Location
Whether the pattern is located at the start or at the end of the messages.
- Max Buffer Age
The maximum age of the buffer after which it is transferred to success when matching
Start of Messagepatterns or to failure when matchingEnd of Messagepatterns.Expected format is
<duration> <time unit>. - Max Buffer Size
The maximum buffer size. If the buffer exceeds this, it is transferred to failure.
Expected format is<size> <size unit>.
Relationships
- Success
The part of the incoming flow files that form cohesive messages.
- Failure
Flowfiles that failed the defragmentation process. This can happen if the buffer size is reached, or if the incoming files originate from different sources.
How to use
Simply connect to a source processor which generates a consecutive stream of text based data (for example, TailFile), and configure the Pattern and Pattern Location properties so that the DefragmentText processor can resegment the data with regex matching.
With the Maximum Buffer Size you can limit how large these flow files can grow (if the pattern matching fails), and with Maximum Buffer Age you can ensure that the messages are sent out even if there is no more incoming data.
The Failure relationship indicates that the data routed to this relationship might not be defragmented (Buffer size limit reached, incoming data is from different sources etc), but no data is lost.
Limitations
- It is a single threaded processor (multi threaded operations are disabled).
- Since this processor can only buffer one flow file at a time, this processor should only be used with a single source.
- When used with TailFile, TailFile should be in Single File mode.
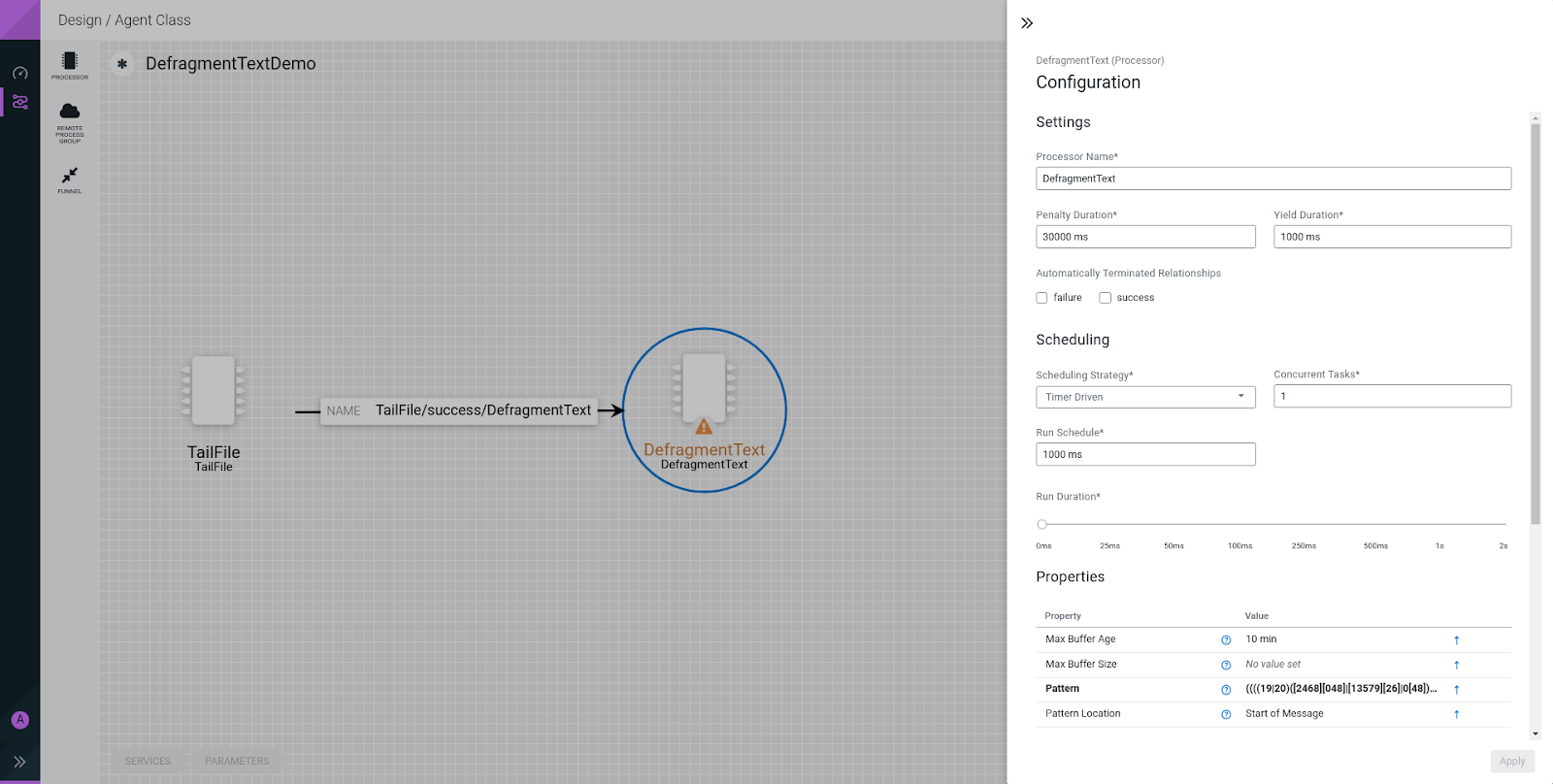
Real world example: Tailing a Java application logfile
TailFile is set up to tail the log file of a Java application. The output of the TailFile is connected to the DefragmentText processor.
(((19|20)([2468][048]|[13579][26]|0[48])|2000)-02-29|((19|20)[0-9]{2}-(0[4678]|1[02])-(0[1-9]|[12][0-9]|30)|(19|20)[0-9]{2}-(0[1359]|11)-(0[1-9]|[12][0-9]|3[01])|(19|20)[0-9]{2}-02-(0[1-9]|1[0-9]|2[0-8])))\s([01][0-9]|2[0-3]):([012345][0-9]):([012345][0-9]))The DefragmentText Pattern Location property is set to the
Start of Message.