Learn how to create a data flow for ingesting data into an Iceberg table in Hive or
Impala.
This process involves leveraging NiFi in your Flow
Management cluster. The example data flow you can see below generates FlowFiles
containing random JSON data and then writes this data into an Iceberg table.
Access the NiFi UI using Cloudera Manager.
Add the GenerateFlowFile processor for data input. This
processor creates FlowFiles with random data or custom content.
Drag and drop the processor icon into the canvas. This displays a
dialog that allows you to choose the processor you want to add.
Select the GenerateFlowFile processor from the
list.
Click Add or double-click the required processor
type to add it to the canvas.
You will configure the GenerateFlowFile processor to
define how to create the sample data in Configuring the processor for
your data source.
Add the PutIceberg processor for data output.
You will configure the PutIceberg processor in
Configuring the processor for your data target.
Connect the two processors to create a flow.
Drag the connection icon from the first processor, and drop it on the second
processor.
A Create Connection dialog appears with two tabs:
Details and
Settings.
Configure the connection.
You can configure the connection's name, flowfile expiration time period, thresholds for back
pressure, load balance strategy and prioritization.
Click Add to close the dialog box and add the
connection to your data flow.
Optional: You can add success and failure funnels to your data flow, which help you see
where flow files are being routed when your flow is running. Connect the
PutIceberg processor to these funnels with success
and failure connections.
If you want to know more about working with funnels, see the Apache NiFi
User Guide.
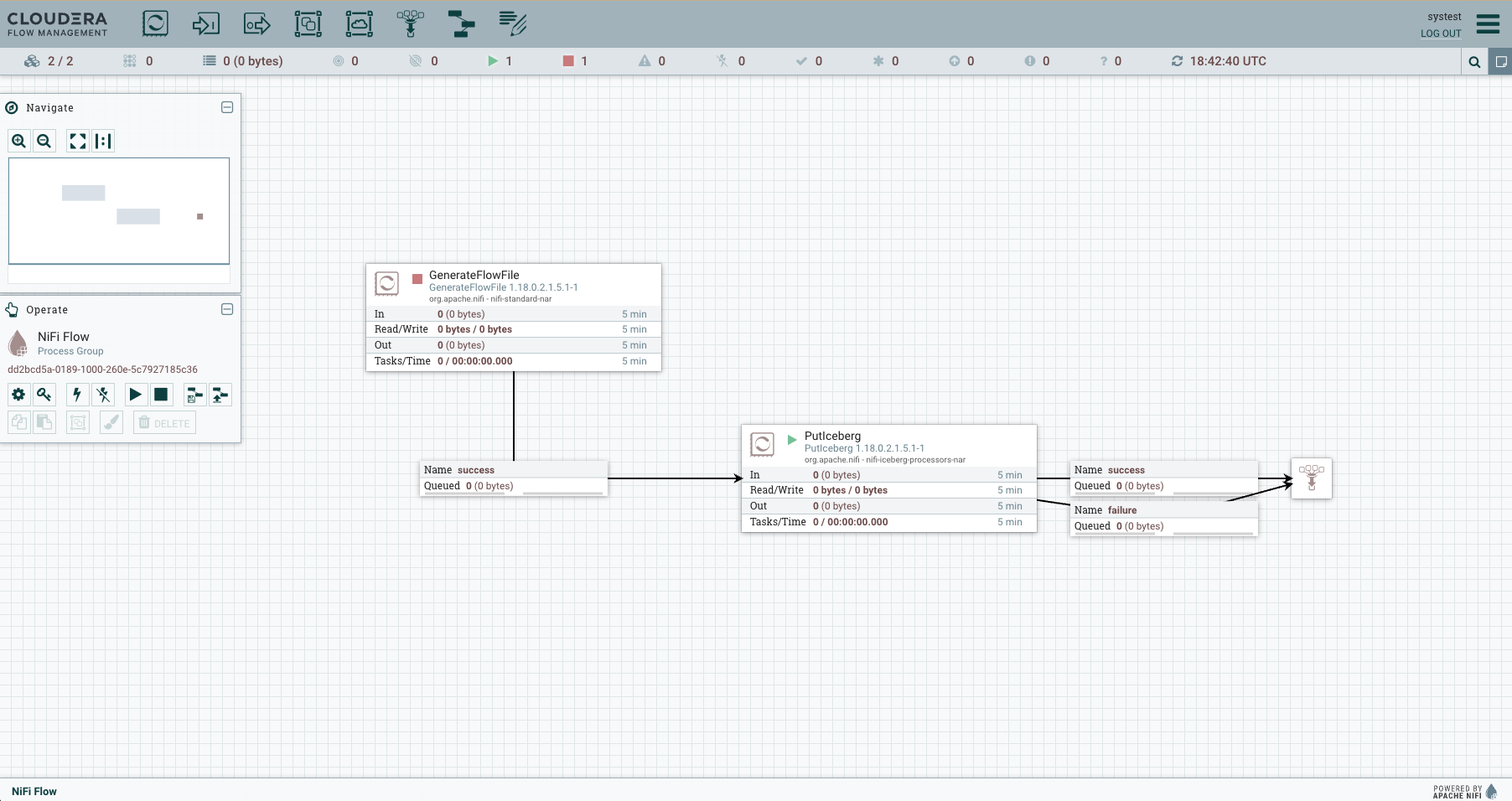
Your data flow will look similar to the following: Create controller services for your data flow. You will need these services when
configuring the PutIceberg processor.