Autoscaler
The Flink Operator offers a job autoscaler functionality that can scale individual job vertices (chained operator groups) based on various metrics collected from running Flink applications.
- Better cluster resource utilization and lower operating costs
- Automatic parallelism tuning for even complex streaming pipelines
- Automatic adaptation to changing load patterns
- Detailed utilization metrics for performance debugging
- Backlog information at each source
- Incoming data rate at the sources (for example, records per sec written into a Kafka topic)
- Number of records processed per second in each job vertex
- Busy time per second of each job vertex (current utilization)
The autoscaler algorithm calculates the required processing capacity and target data rate for each operator starting from the source. The target data rate for the source vertices is equal to the incoming data rate. For downstream operators, the target data rate is calculated as the sum of the input (upstream) operators output data rate along the given edge in the processing graph.
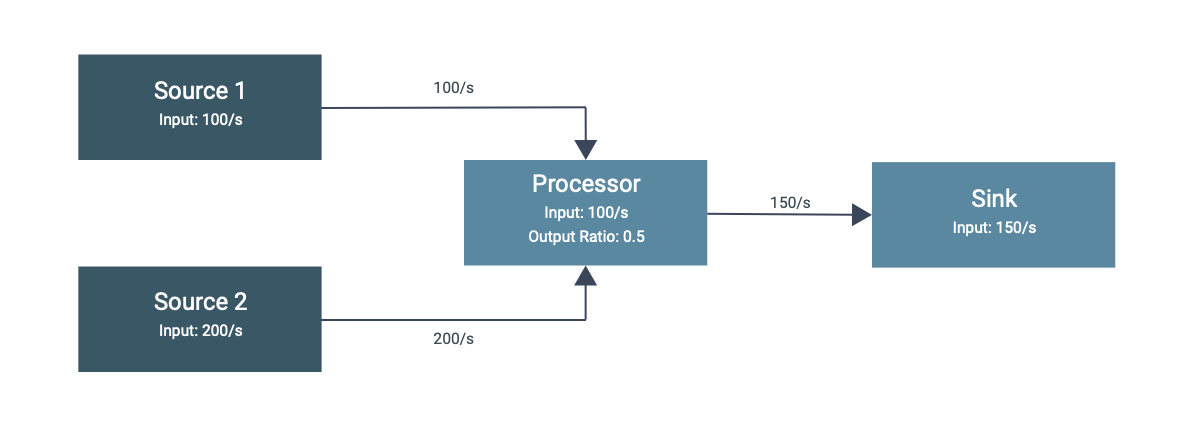
The target utilization percentage of the operators can be configured in the pipeline. For example, you can keep all operators busy between 60% and 80%. The autoscaler will find a parallelism configuration that matches the output rates of all operators with the input rates of all downstream operators at the targeted utilization. As the load increases or decreases, the autoscaler adjusts the parallelism levels of the individual operator to fulfill the current rate over time.