Learn more about the specific details of Flink architecture, the DataStream API, how
Flink handles event time and watermarks, and how state management works in Flink.
Architecture
The two main components for the task execution process are the Job Manager and Task
Manager. The Job Manager on a master node starts a worker node. On a worker node the Task
Managers are responsible for running tasks and the Task Manager can also run more than one
task at the same time. The resource management for the tasks are completed by the Job manager
in Flink. In a Flink cluster, Flink jobs are executed as YARN applications. HDFS is used to
store recovery and log data, while ZooKeeper is used for high availability coordination for
jobs.
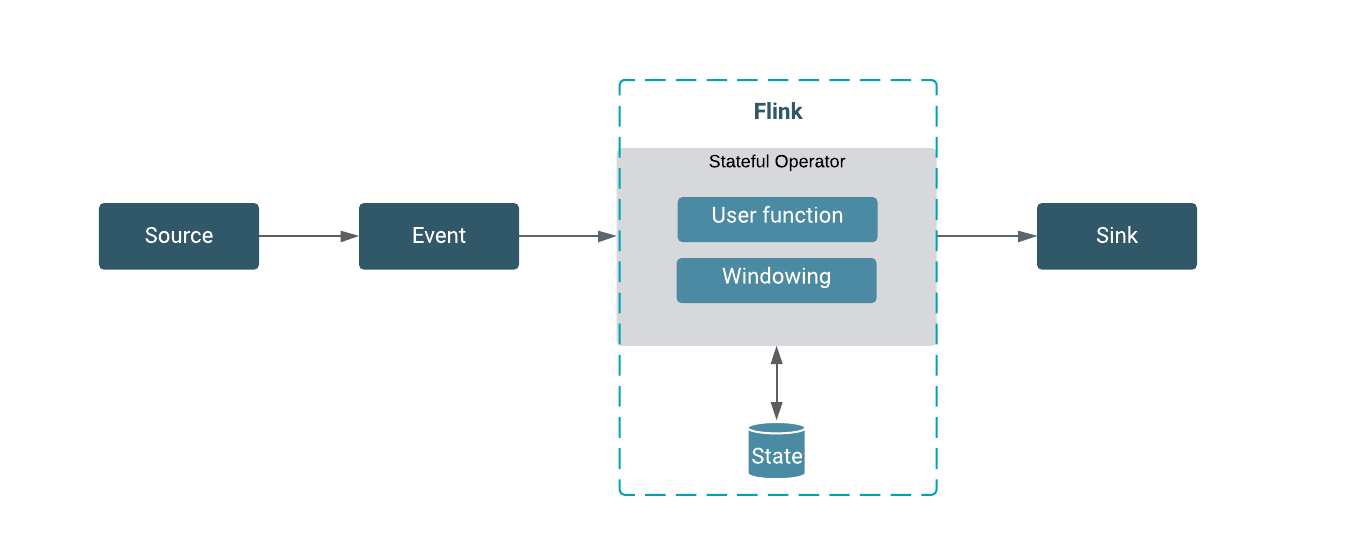
DataStream API
The DataStream API is used as the core API to develop Flink streaming applications using
Java or Scala programming languages. The DataStream API provides the core building blocks of
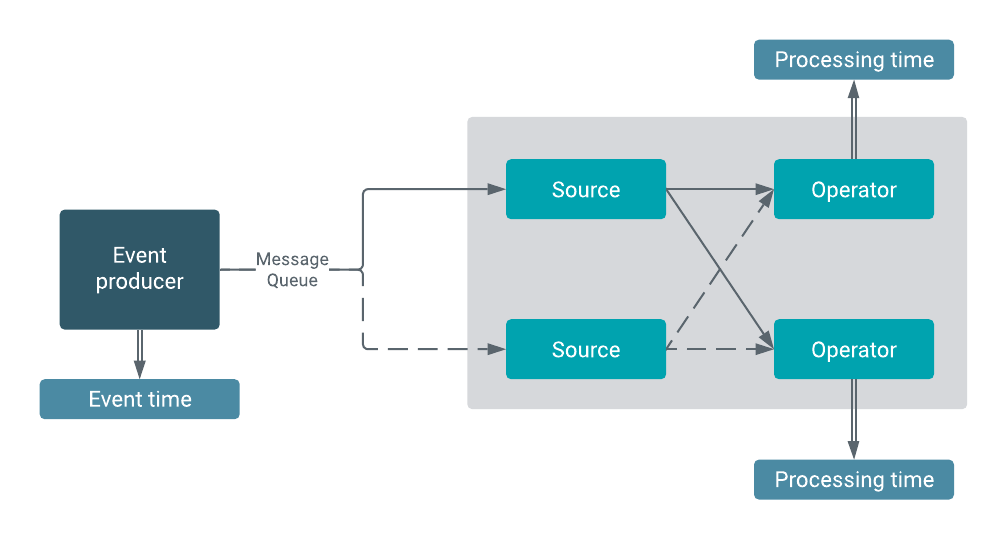
the Flink streaming application: the datastream and the transformation on it. In a Flink
program, the incoming data streams from a source are transformed by a defined operation which
results in one or more output streams to the sink.
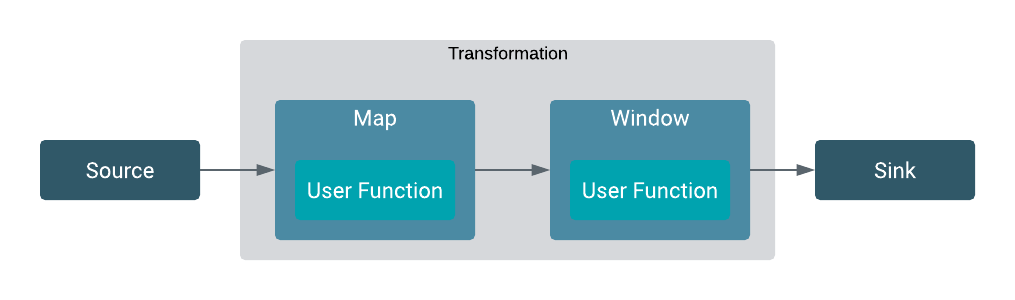
Operators
Operators transform one or more DataStreams into a new DataStream. Programs can combine
multiple transformations into sophisticated data flow topologies. Other than the standard
transformations like map, filter, aggregation, you can also create windows and join windows
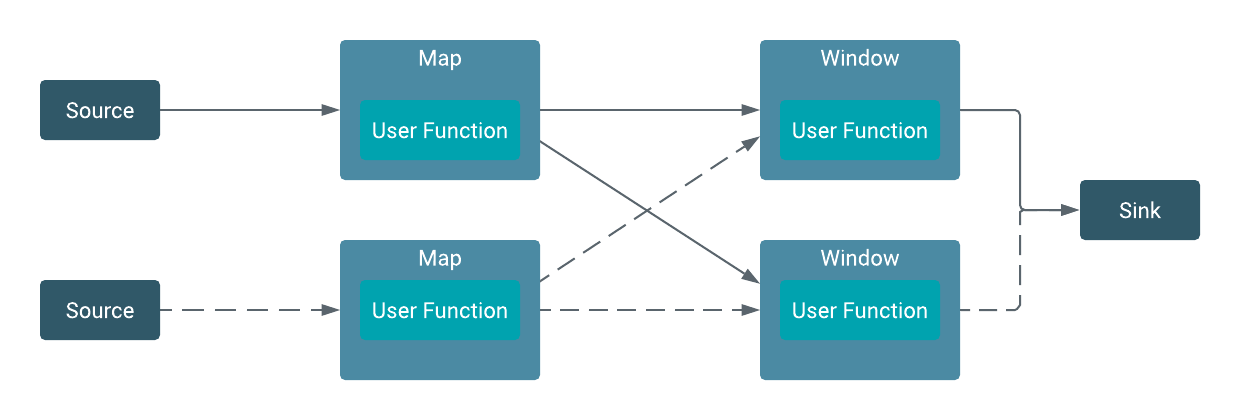
within the Flink operators. On a dataflow one or more operations can be defined which can be
processed in parallel and independently to each other. With windowing functions, different
computations can be applied to different streams in the defined time window to further
maintain the processing of events. The following image illustrates the parallel structure of
dataflows.
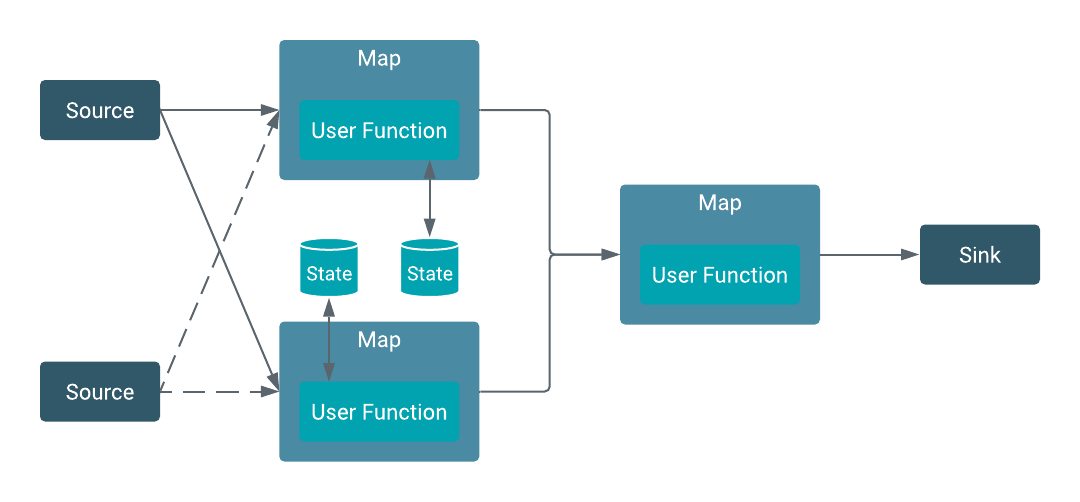
State and state backend
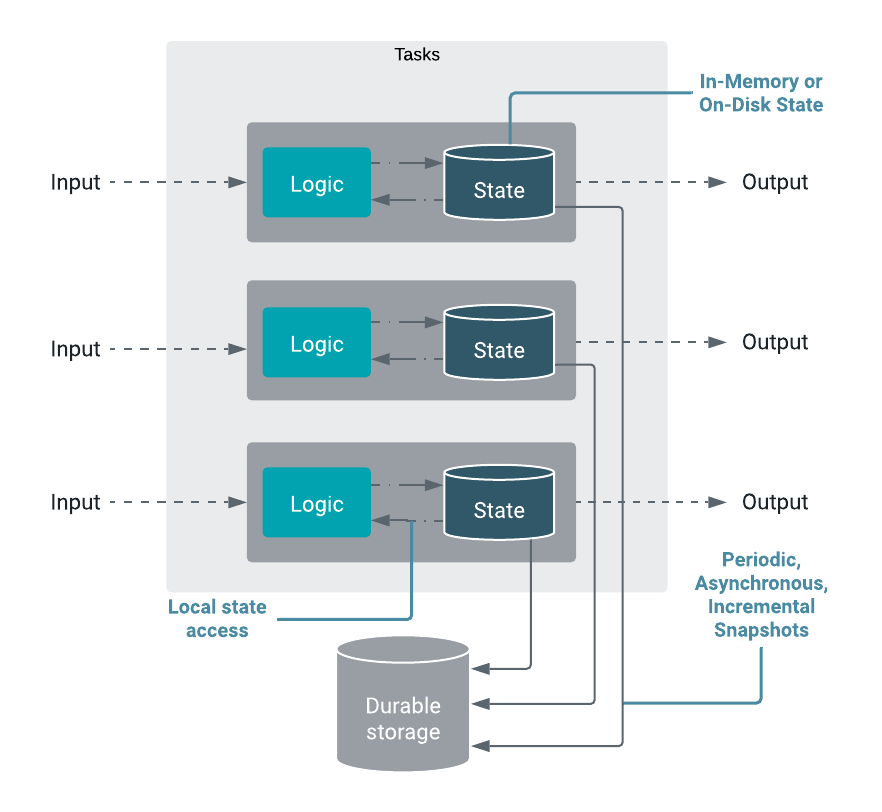
Stateful applications process dataflows with operations that store and access information
across multiple events. You can use Flink to store the state of your application locally in
state backends that guarantee lower latency when accessing your processed data. You can also
create checkpoints and savepoints to have a fault-tolerant backup of your streaming
application on a durable storage.
Event time and watermark
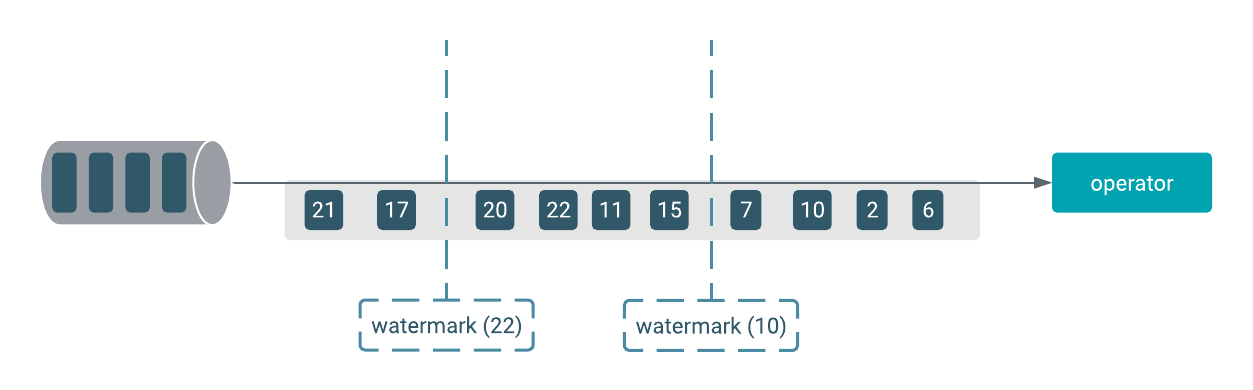
In time-sensitive cases where the application uses alerting or triggering functions, it is
important to distinguish between event time and processing time. To make the designing of
applications easier, you can create your Flink application either based on the time when the
event is created or when it is processed by the operator. With only the event time, it is not clear when the events are processed in the
application. To track the time for an event time based application, watermark can be used.
Checkpoints and savepoints
Checkpoints and savepoints can be created to make the Flink application fault tolerant
throughout the whole pipeline. Flink contains a fault tolerance mechanism that creates
snapshots of the data stream continuously. The snapshot includes not only the dataflow, but
the state attached to it. In case of failure, the latest snapshot is chosen and the system
recovers from that checkpoint. This guarantees that the result of the computation can always
be consistently restored. While checkpoints are created and managed by Flink, savepoints are
controlled by the user. A savepoint can be described as a backup from the executed
process.