Creating Python User-defined Functions
With SQL Stream Builder, you can create powerful custom functions in Python to enhance the functionality of SQL.
Python UDFs are disabled by default. To enable them:
- Python UDF execution requires a supported Python version installed on all nodes.
- Access your SSB node's command line. (Execute the following commands as
root. - Download the Python package:
curl -O https://www.python.org/ftp/python/[***FULL VERSION***]/Python-[***FULL VERSION***].tgz - Extract the package contents:
tar -xzf Python-[***FULL VERSION***].tgz - Change to the extracted directory:
cd Python-[***FULL VERSION***] - Configure the Python package:
./configure - Install the Python package:
make install - Install the Python Apache Flink and dependent packages:
/usr/local/bin/python[***VERSION***] -m pip install apache-flink==1.19.1
- Access your SSB node's command line. (Execute the following commands as
- Go to your cluster in Cloudera Manager.
- Select SQL Stream Builder from the list of services.
- Go to the Configuration tab and set the following configuration properties:
- Python Client Executable (
ssb.python.client.executable): the path of the Python interpreter used to launch the Python process when submitting the Python jobs viaflink runor compiling the jobs containing Python UDFs. For example/usr/bin/python3 - Python Executable (
ssb.python.executable): the path of the Python interpreter used to execute the python UDF worker. For example/usr/bin/python3 - Python UDF Reaper Period (
ssb.python.udf.reaper.period.seconds): the interval (in seconds) between two Python UDF Reaper runs, which deletes the Python files of the terminated jobs from the artifact storage. - Python UDF Time To Live (
ssb.python.udf.ttl): The minimum lifespan (in milliseconds, seconds, minutes, or hours) of a Python UDF in the artifact storage. After this the Python UDF Reaper can delete the Python files from the artifact storage. - Select Enable Python UDFs in SSB (
ssb.python.udf.enabled) and click on the checkbox.
- Python Client Executable (
- Enter a reason for change and click Save Changes.
- Navigate to Instances.
- Select the Streaming SQL Engine from the list. (Click the checkbox on the left.)
- Click Restart from the Actions for selected dropdown menu.
To use Python UDFs:
-
Click
 next to Functions.
next to Functions.
-
Click New Function.
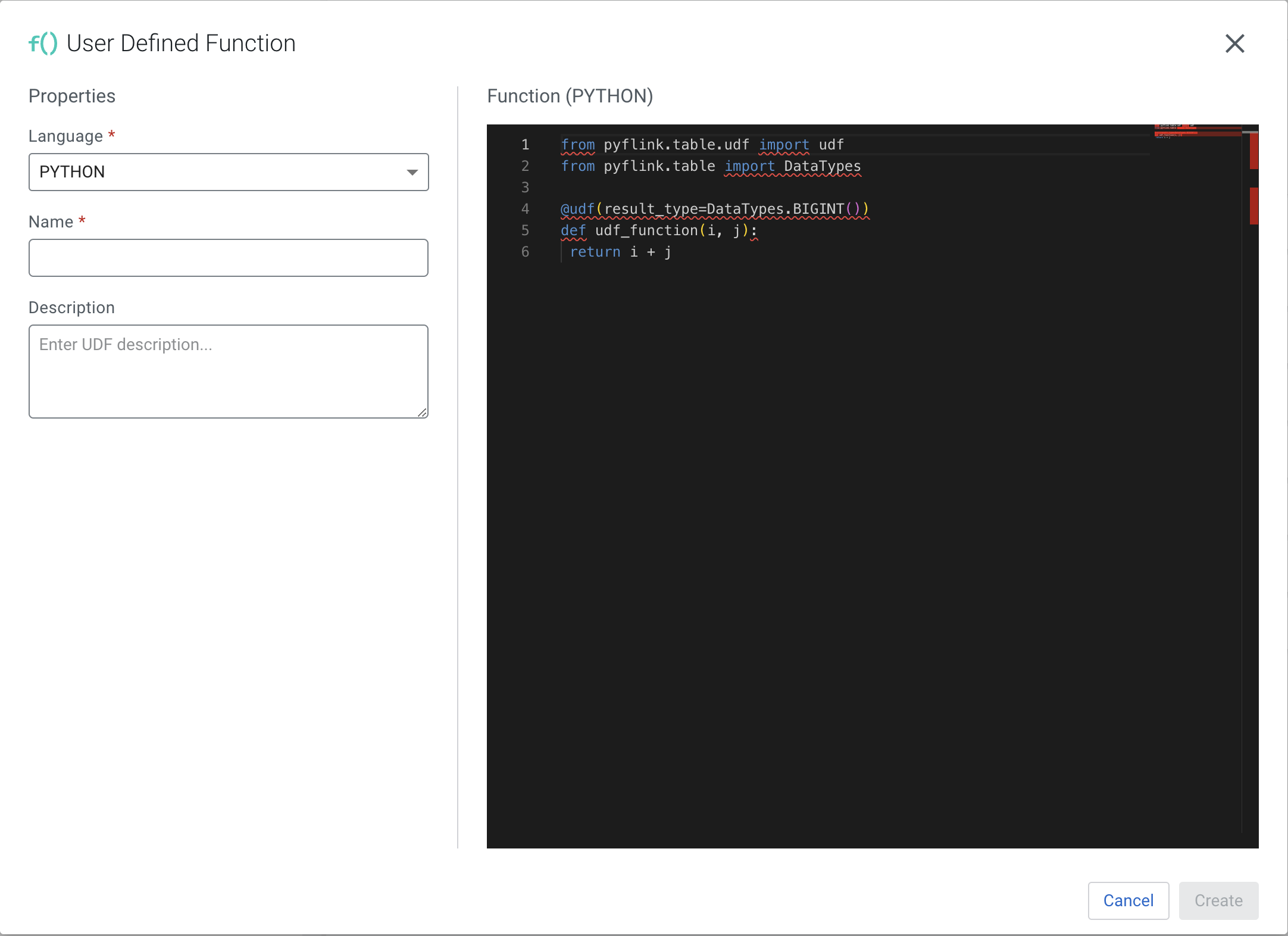
When a Flink job starts, SSB will upload the Python file to the Artifact Storage, accessible for Flink to execute the UDF when called. The ssb.python.udf.reaper.period.seconds and ssb.python.udf.ttl configuration properties (set in Cloudera Manager) control the behavior of SSB to remove Python files associated with terminated jobs.
For more information on using Python UDFs, refer to the Apache Flink documentation.