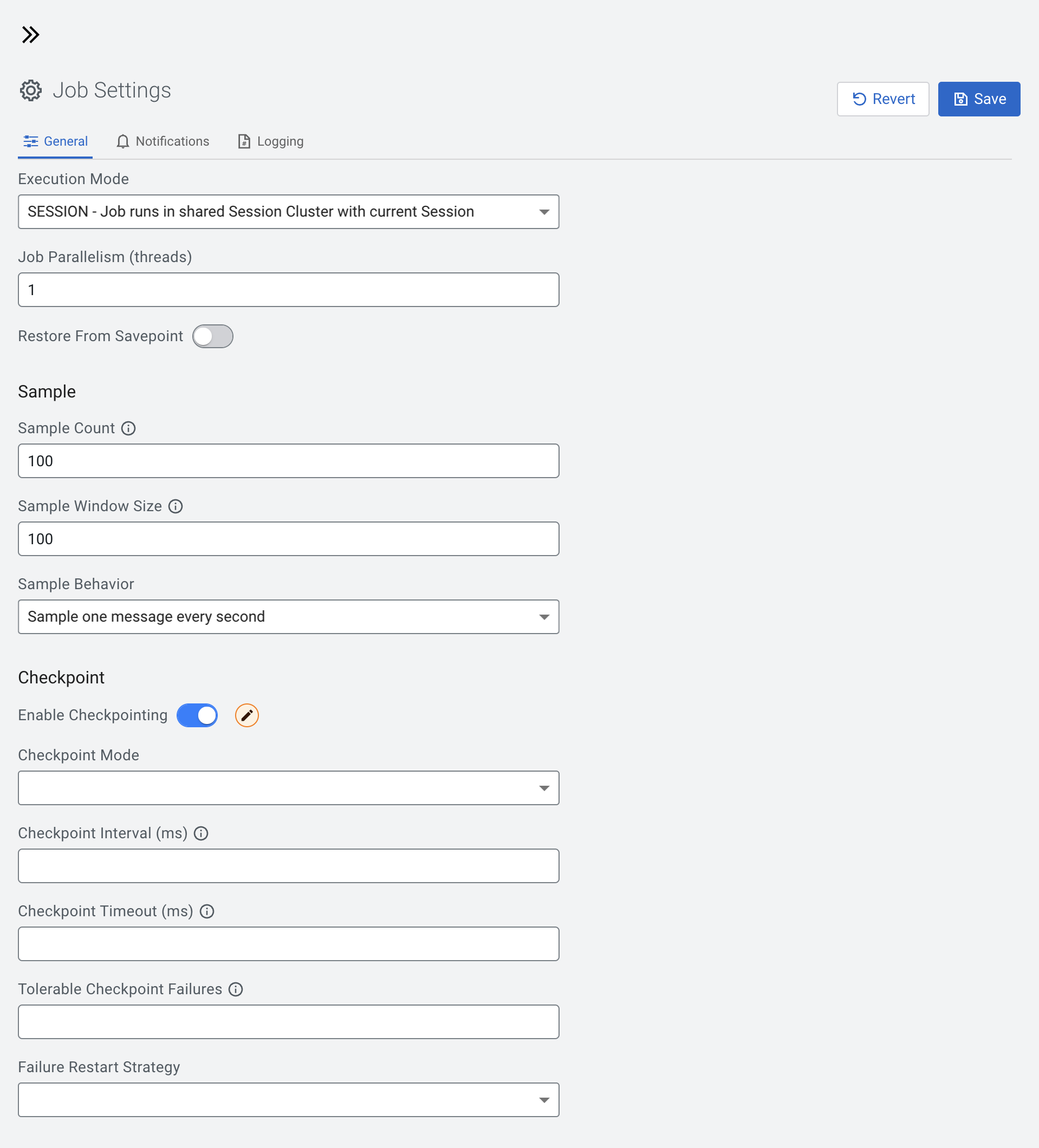
If you need to further customize your SQL Stream job, you can add more advanced
features to configure the job restarting method and time, threads for parallelism, sample
behavior, exactly once processing and restoring from savepoint.
Before running a SQL query, you can configure advanced features by clicking on the
Job Settings button at the SQL Editor.
Execution Mode
You can select the execution mode for the SQL job that can be a session or a per-job
mode. For more information, see the Executing SQL jobs in production
mode
documentation.
Job parallelism (threads)
The number of threads to start to process the job. Each thread consumes a slot on the
cluster. When the Job Parallelism is set to 1, the job consumes the least resources. If
the data source supports parallel reads, increasing the parallelism can raise the maximum
throughput. For example, when using Kafka as a data source, setting the parallelism to the
equal number as the partitions of the topic can be a starting point for performance
tuning.
Restore From Savepoint
You can enable or disable restoring a SQL job from a Flink savepoint after stopping it.
The savepoint is saved under hdfs:///user/flink/savepoints by
default.
Sample Count
The number of sample entries to poll before sampling stops. To poll an unlimited number of
sample entries, add 0 as the Sample Count value.
Sample Window Size
The number of sample entries from active sampling displayed in the Results tab. To display an unlimited
number of sample entries, add 0 as the Sample Window Size value.
Sample Behavior
You have the following options to choose the behavior of the sampled data under the
Results tab:
Sample all messages
Sample one message every second
Sample one message every five seconds
Enable Checkpointing
You can enable and disable checkpointing for a SQL job. By default the checkpointing is
enabled.
Checkpoint Mode
Switching between checkpointing modes. You can choose between At Least Once or Exactly
Once.
Checkpoint Interval
The time in milliseconds between checkpointing attempts.
Checkpoint Timeout
The maximum time in milliseconds until a checkpointing attempt is timed out.
Tolerable Checkpoint Failures
The number of checkpointing attempts until the job is aborted.
Failure Restart Strategy
Switching between restarting strategies when checkpointing is failed. You can choose
between enabling and disabling auto recovery. By default auto recovery is enabled for
checkpointing.