Conceptual differences
Storm and Flink can process unbounded data streams in real-time with low latency. Storm uses tuples, spouts, and bolts that construct its stream processing topology. For Flink, you need sources, operators, and sinks to process events within its data pipeline. Other than the terminology, the two systems handle state differently. Furthermore, Flink has an event windowing function to achieve exatly-once processing.
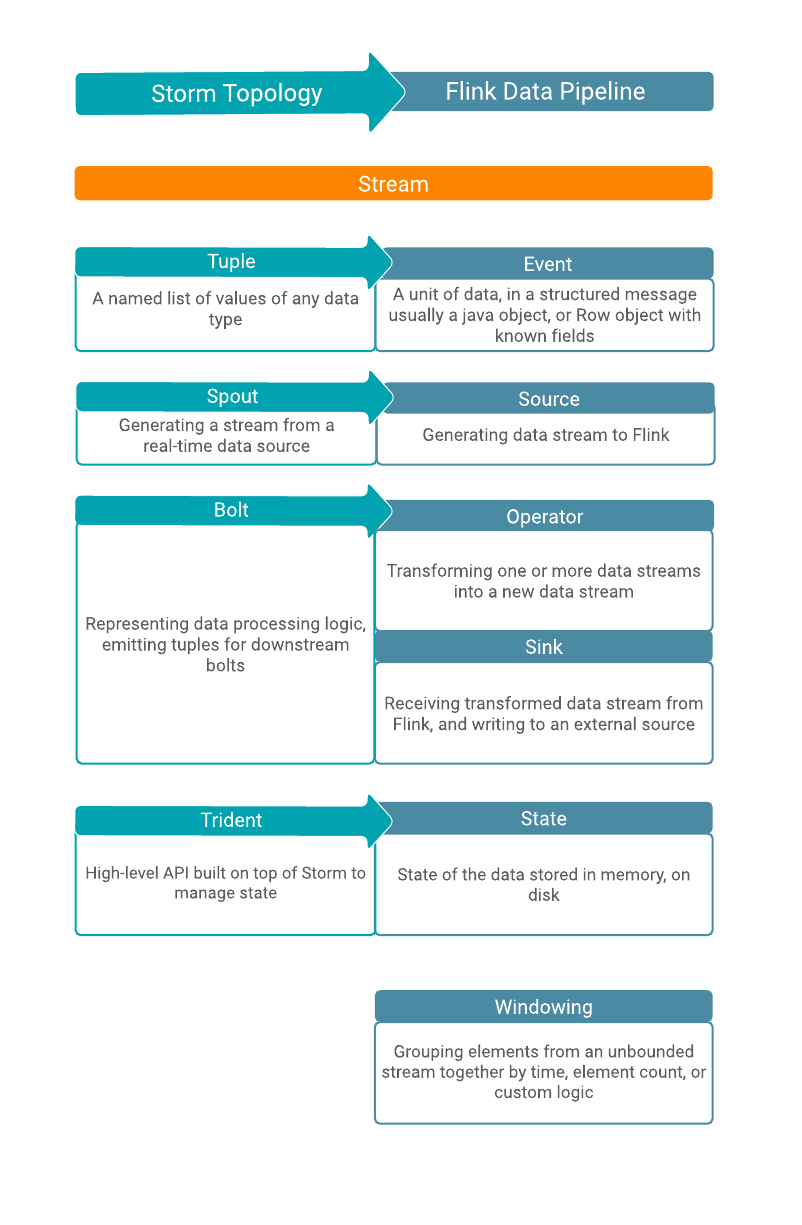
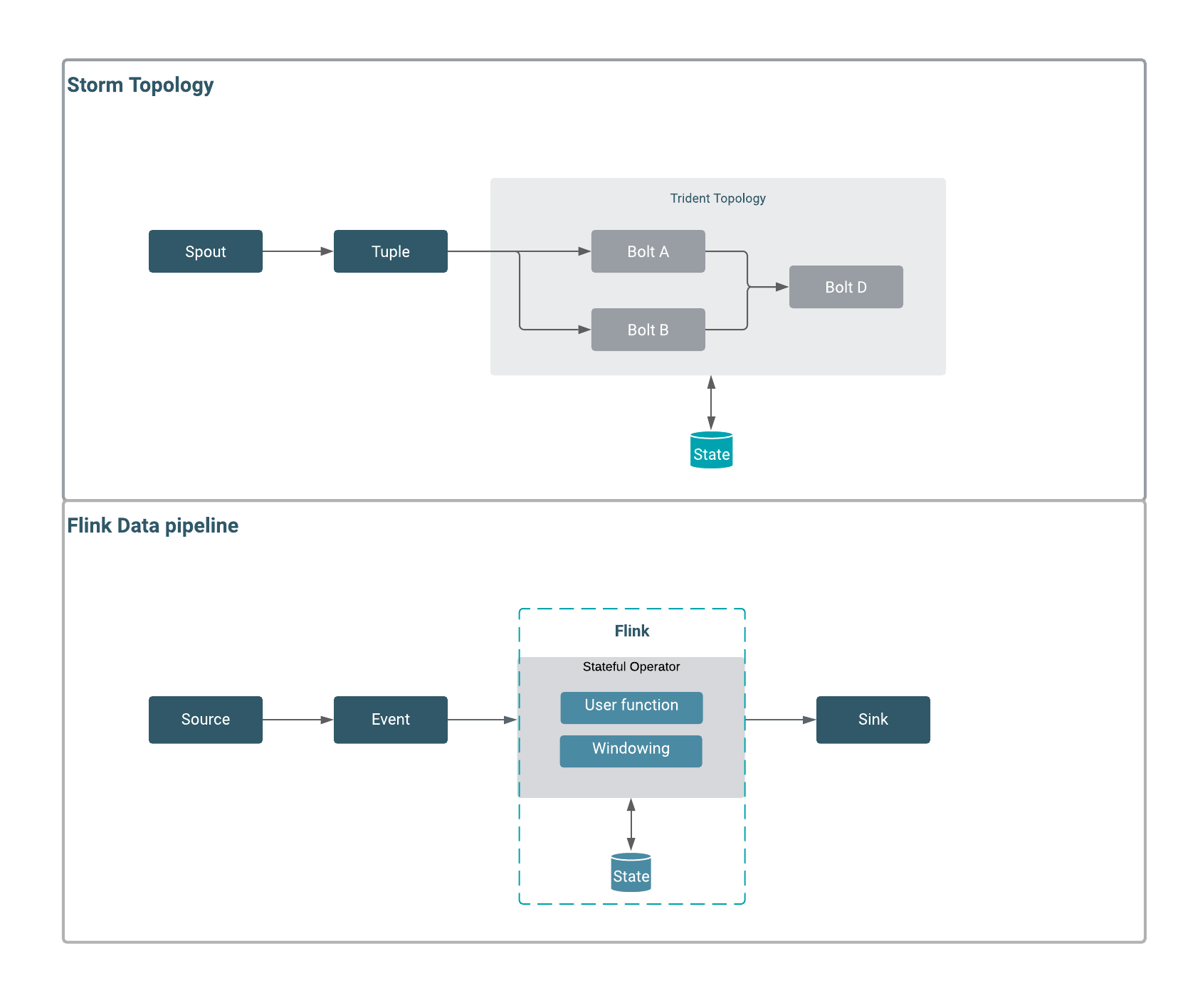
In a Flink program, the incoming data from a source are transformed by a defined operation which results in one or more output streams. The transformation or computation on the data is completed by an operator where you can also add windowing function or join data streams. The main conceptual difference between Storm and Flink is state handling. While you need Trident API to manage state and fault tolerancy in Storm, Flink handles state in-memory and on disk, which makes the process of checkpointing and state management faster in Flink. This also makes the maintenance, troubleshooting, and upgrading processes easier in Flink, because the state of an application and the state of the different operators within the data pipeline are saved. The following illustration details how these concepts in Storm and Flink structure of their dataflow.
| Storm Connectors | Flink Connectors | ||
|---|---|---|---|
| Spout | Kafka | Source | Kafka |
| HDFS | HDFS | ||
| Bolt | Kafka | Sink | Kafka |
| HBase | HBase | ||
| Hive | Kudu | ||
| HDFS | HDFS | ||
| Hive | |||