A job in Cloudera Data Engineering (CDE) consists of defined
configurations and resources (including application code). Jobs can be run
on demand or scheduled.
In Cloudera Data Engineering (CDE), jobs are associated with virtual
clusters. Before you can create a job, you must create a virtual cluster
that can run it. For more information, see Creating virtual clusters.
In the Cloudera Data Platform (CDP) console, click the
Data Engineering tile. The CDE Home page
displays.
In the CDE Home page, in Jobs, click
Create New under Spark or click
Jobs in the left navigation menu and then click Create
Job.
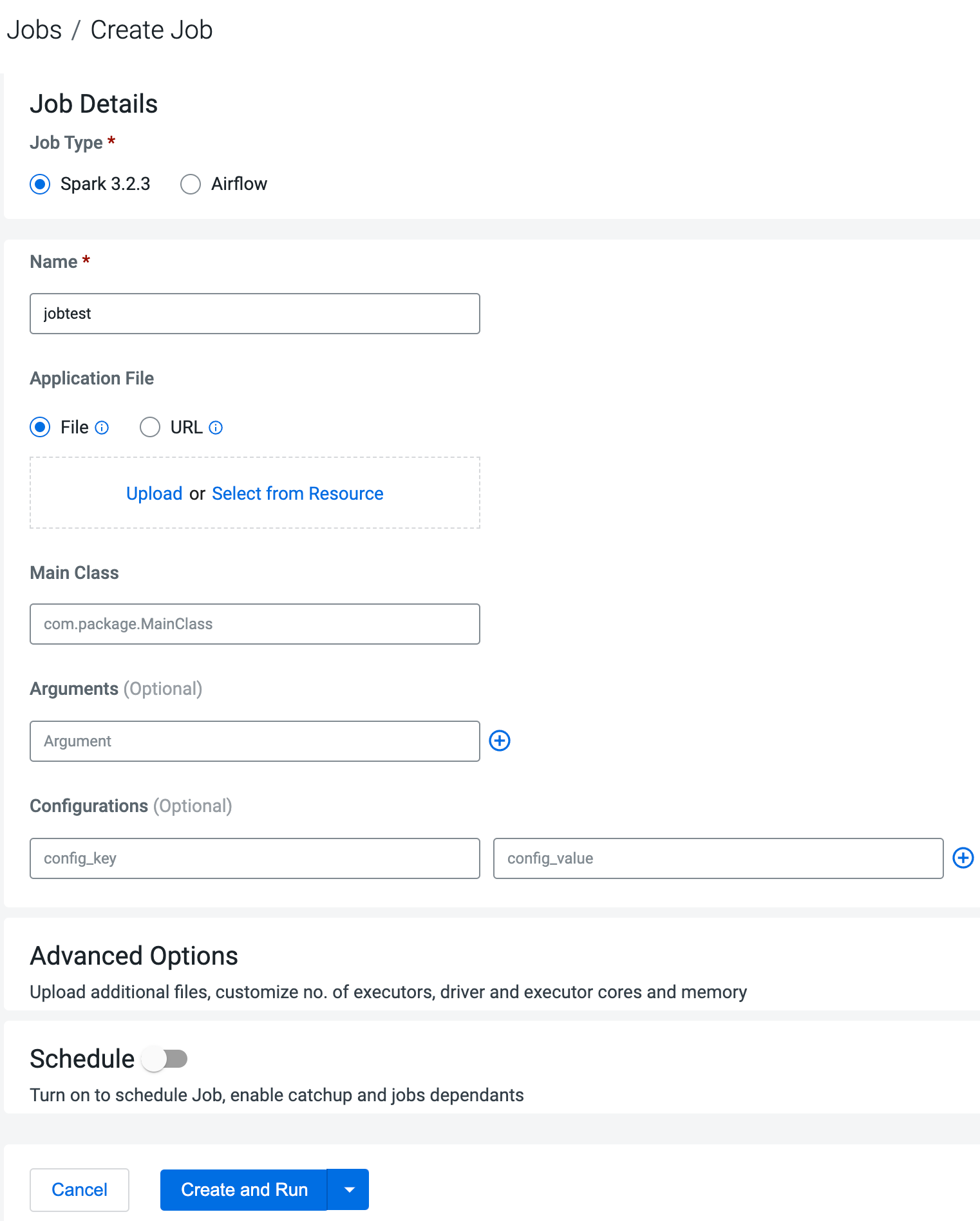
Provide the Job Details:
Select Spark for the job type. If you are creating the job
from the Home page, select the virtual cluster where you want
to create the job.
Specify the Name.
Select File or
URL for your application file, and
provide or specify the file. You can upload a new file or select a
file from an existing resource.
If you select the URL option and specify an Amazon AWS S3 URL, add the following configuration
to the job:
If your application code is a JAR file, specify the
Main Class.
Specify arguments if required. You can click the
Add Argument button to add multiple
command arguments as necessary.
Enter Configurations if needed.
You can click the Add Configuration button
to add multiple configuration parameters as
necessary.
Optional: Select the name of the data connector from the Data
Connector drop-down list. The UI displays the storage information that
is internally overwritten.
If your application code is a Python file, select the
Python Version, and optionally select a
Python Environment.
Click Advanced Configurations to display more customizations,
such as additional files, initial executors, executor range, driver and executor cores,
and memory.
By default, the executor range is set to match the range of CPU cores configured for
the virtual cluster. This improves resource utilization and efficiency by allowing jobs to
scale up to the maximum virtual cluster resources available, without manually tuning and
optimizing the number of executors per job.
Click Schedule to display scheduling
options.
You can schedule the application to run
periodically using the Basic controls or by
specifying a Cron Expression.
Click Alerts and provide the email id to receive alerts. Click
+ to add more email IDs. Optionally, you can select when you want
email alerts whether for job failures or missed job service-level agreements or both.
If you provided a schedule, click
Schedule to create the job. If you did not
specify a schedule, and you do not want the job to run immediately,
click the drop-down arrow on Create and Run and
select Create. Otherwise, click
Create and Run to run the job
immediately.