
Creating virtual clusters
In Cloudera Data Engineering (CDE), a virtual cluster is an individual auto-scaling cluster with defined CPU and memory ranges. Jobs are associated with virtual clusters, and virtual clusters are associated with an environment. You can create as many virtual clusters as you need.
To create a virtual cluster, you must have an environment with Cloudera Data Engineering (CDE) enabled.
- In the Virtual Clusters column, click
 at the top right to create a new virtual
cluster.If the environment has no virtual clusters associated with it, the page displays a Create DE Cluster button that launches the same wizard.
at the top right to create a new virtual
cluster.If the environment has no virtual clusters associated with it, the page displays a Create DE Cluster button that launches the same wizard.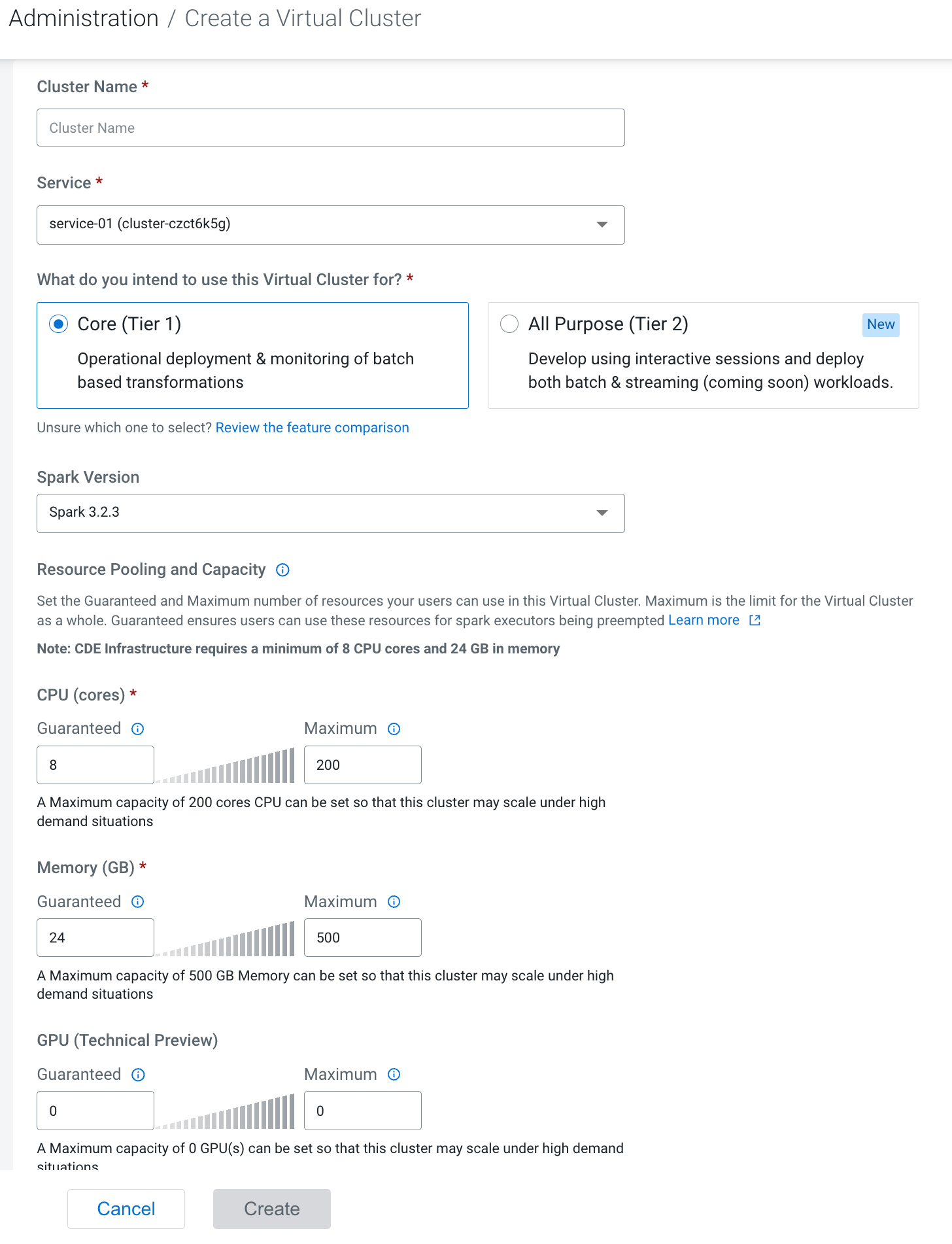
You must initialize each virtual cluster you create and configure users before creating jobs.
Cloudera Data Engineering provides a suite of example jobs with a combination of Spark and Airflow jobs, which include scenarios such as reading and writing from object storage, running an Airflow DAG, and expanding on Python capabilities with custom virtual environments. For information about running example jobs, see CDE example jobs and sample data.