Connecting Cloudera Data Engineering to Apache Kafka
Apache Kafka powers Cloudera Data Engineering by providing a resilient messaging backbone for real-time data ingestion, routing, and decoupled event-driven architectures. Connect to Kafka using Cloudera Data Engineering and produce and consume data to and from Kafka topics on the base cluster.
- You must download the following JAR files for compiling Scala
application:
- kafka-clients-[***KAFKA-CLOUDERA-RUNTIME-VERSION***].jar
- spark-sql-kafka-0-10_2.12-[***SPARK3-CLOUDERA-RUNTIME-VERSION***].jar
- spark-core_2.12-[***SPARK3-CLOUDERA-RUNTIME-VERSION***].jar
- spark-sql_2.12-[***SPARK3-CLOUDERA-RUNTIME-VERSION***].jar
- You must create a configuration file named
kafka_client_jaas.conf with the following
content:
KafkaClient { com.sun.security.auth.module.Krb5LoginModule required useTicketCache=true serviceName="kafka"; }; - You must get the Kafka bootstrap servers from the base cluster.
- Sign in to Cloudera Manager.
- In the left navigation menu, click Clusters.
- Select the Kafka cluster.
- Go to the Configuration tab.
- Search for Bootstrap Servers and record the
displayed value.
Figure 1. Bootstrap Servers value 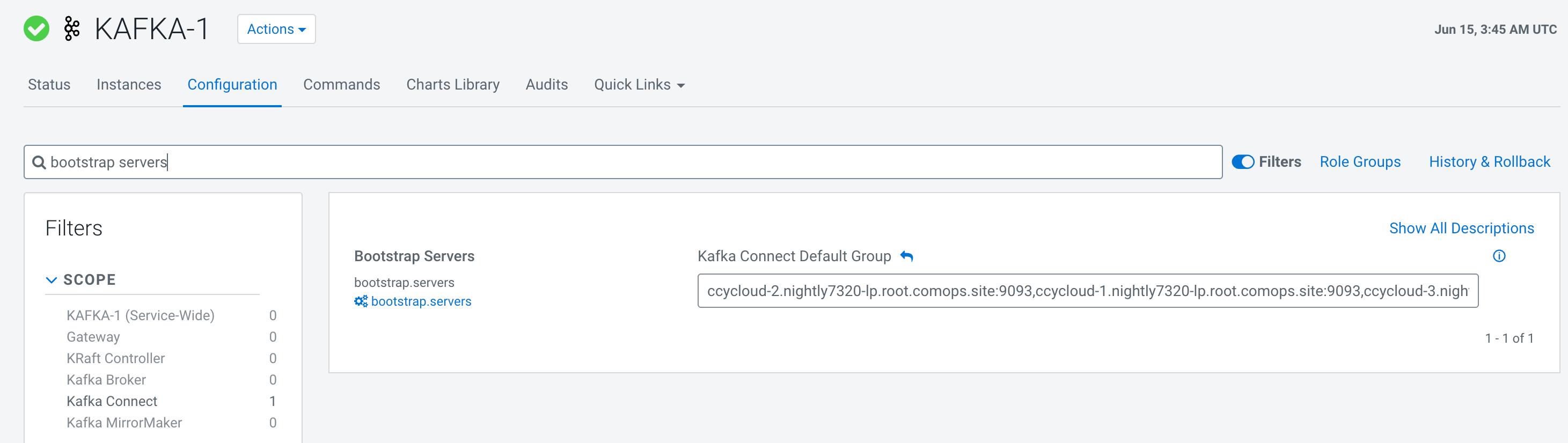
- You must set up a Kafka topic in the Kafka base cluster.
- Sign in to Cloudera Manager.
- In the left navigation menu, click Clusters.
- Select the Kafka cluster.
- Go to the Instances tab.
- Search for the Kafka broker and copy the Kafka Broker node host
name.
Figure 2. Kafka Broker ID and hostname 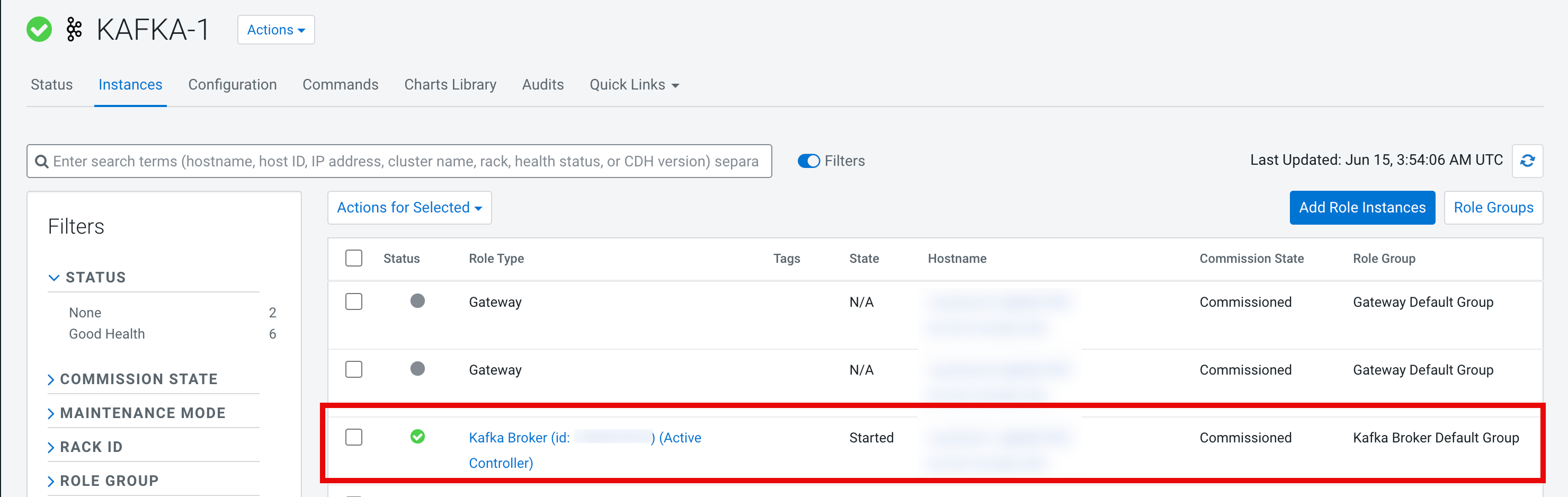
- Open your terminal and SSH into the Kafka Broker node.
- Create a new file named kafka-temp.properties in
the Kafka Broker node with the following
content:
security.protocol=SASL_SSL sasl.mechanism=GSSAPI sasl.jaas.config=com.sun.security.auth.module.Krb5LoginModule required useKeyTab=false useTicketCache=true client=true debug=true; sasl.kerberos.service.name=kafka ssl.truststore.location=/var/lib/cloudera-scm-agent/agent-cert/cm-auto-global_truststore.jks - Authenticate using
kinitwith a Kafka administrator account or any workload user that hasCreateaccess to all topics (*) or a specific topic. - Create the Kafka topic by running the following
command:
$ kafka-topics --create --bootstrap-server [***KAFKA-BOOTSTRAP-SERVERS***] --replication-factor 1 --partitions 1 --topic spark-kafka --command-config kafka-temp.properties
- You must provide consumer, producer, and cluster roles to the user using the Ranger UI. For more information, see Configure a resource-based policy: Kafka.