Cloudera Data Engineering tier types
Learn more about the available tier types that you can use in your Cloudera Data Engineering Service.
Overview
On the Cloudera Data Engineering UI, DE and Platform administrators can create new Virtual Clusters and select the required cluster type at .
Cloudera Data Engineering offers these cluster types:
- Core
- All Purpose
In the same Cloudera Data Engineering Service, you can run some workloads on Core and some workloads on All purpose clusters.
Tier functionalities
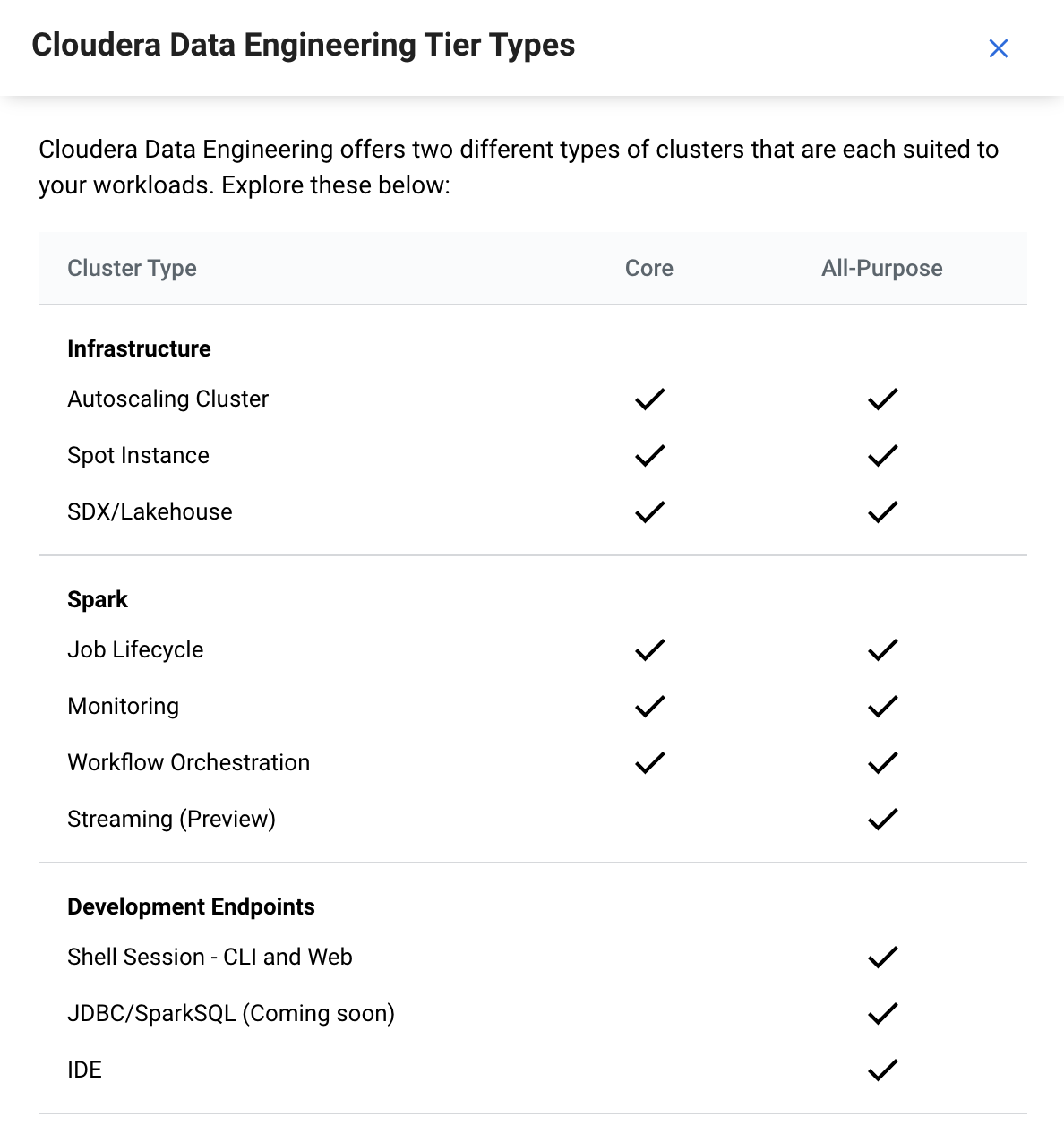
On the Core Tier, you can develop jobs for operational deployment and monitor batch based transformations.
Core Tier functionalities:
- Autoscaling cluster
- Spot instances
- Cloudera Shared Data Experience
- Open Lakehouse with Iceberg
- Job lifecycle management
- Centralized monitoring
- Workflow orchestration (Airflow)
On the All Purpose Tier, you can develop jobs using interactive sessions and deploy both batch and streaming (preview) workloads.
All Purpose Tier functionalities:
- Interactive sessions
- External IDE connectivity
- Spark streaming
- JDBC connector (Coming soon)
The following screenshot from the Cloudera Data Engineering UI provides a detailed feature comparison for the Core and All Purpose Tiers.
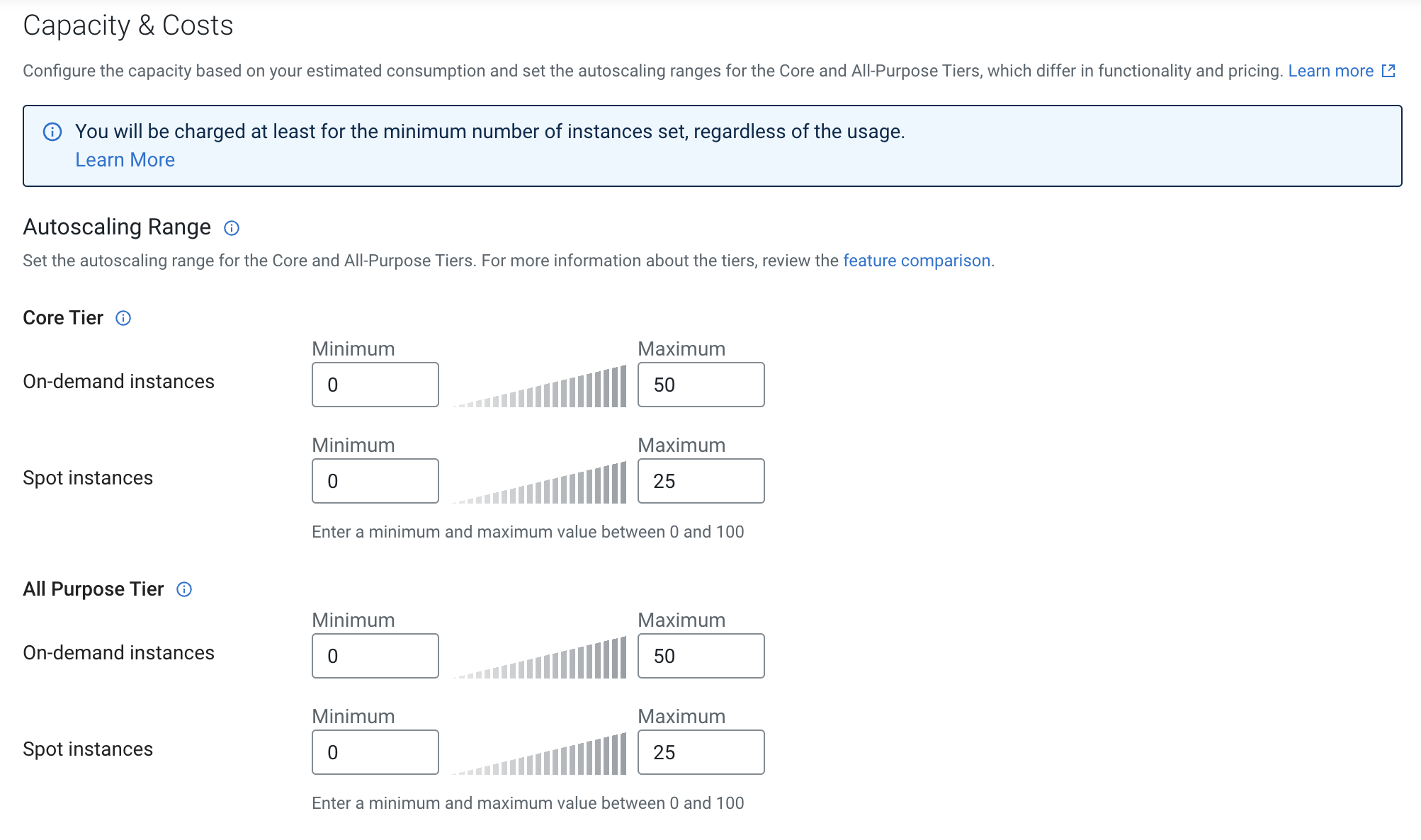
Autoscaling range considerations for tier and instance types
In the Cloudera Data Engineering UI, in the section, you can set the autoscale range for the Core Tier and for the All Purpose Tier.
In the Capacity & Costs section, you can configure the autoscaling range for On-demand instances and if you select an AWS environment, for Spot instances as well. Currently, Spot instances in Azure are not supported in Cloudera Data Engineering.
The key difference between On-demand instances and Spot instances is that On-demand instances are consistently available, while the availability of Spot instances depends on the cloud provider.
You can use Spot instances and All Purpose Spot instances to save compute costs. Fore more information about Spot instances, see Cloudera Data Engineering Spot Instances and the AWS document, Amazon EC2 Spot Features.
Important factors to consider before using All purpose On-demand instances
With All Purpose On-demand Instances, consider the following:
- Since version 1.20.3, Cloudera Data Engineering offers price tiering to provide better cost-control for the consumed features.
- To avoid being charged for All Purpose compute nodes, set the minimum value of All
Purpose On-demand Instances to
0. However, in such a case, consider that if you create a new session, the session can take several minutes to start.