Manually recovering from load-based scaling failures
The mechanics for scaling are straightforward. There are four operations performed, and instances are not deleted during a load-based scale-down. Scale-up and scale-down operations are also meant to fail relatively fast, so that manual repair operations, if necessary, can be performed faster. Additionally, these operations can also be performed if there is another Management Operation (other than scaling) already in progress, which would otherwise block scaling.
The operations performed during a load-based scale-up and scale-down are outlined below.
- Scaleup: Start Instances on Cloud Provider: Specific instances for scale-up are started via the cloud provider. This can be replicated manually by changing the ‘Instance State’ on the cloud provider console.
- Scaleup: Commission Services via Cloudera Manager: The next
step is to commission the services on these nodes. To replicate this manually, find these
hosts using the filter: Status: Good Health, CommissionState:
Decommissioned. Select them, then click .
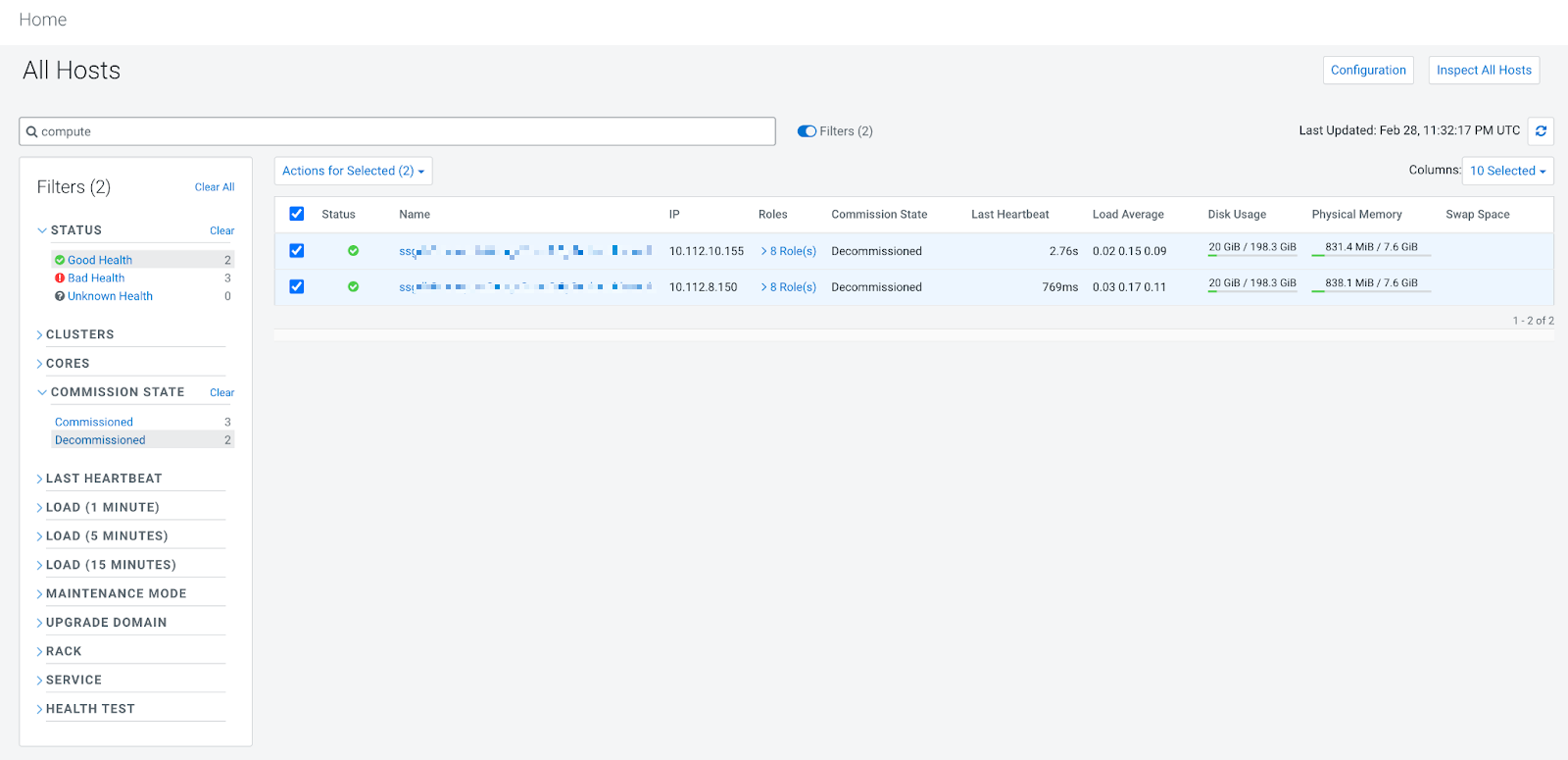
- Scale-down: Decommission Services via Cloudera Manager: This is the first step of a downscale operation. This can be replicated manually by selecting the relevant hosts in ClouderaManager as above, then click .
- Scale-down: Stop Instances on Cloud Provider: This is the second step of a scale-down operation, and specific instances are stopped via AWS or Azure. This can be replicated manually by changing the ‘Instance State’ on the cloud provider console.
Given the simplicity of the operations, and the fact that all the operations can be easily
replicated by a cluster administrator, most failures can be handled quickly by following one
or more of the procedures above. Some specific scenarios are outlined below.
- Scale-up failures, where capacity is required
-
- On the Autoscale tab for the cluster, use the toggle to disable autoscaling on the cluster.
- Find stopped instances on the cloud provider console for the specific host group, and start them.
- Wait for a few minutes for the instances to show up marked as "healthy" in Cloudera Manager (use the filter: Status: Good Health, Commission State: Decommissioned). Select instances from the appropriate host group and End Maintenance.
- Cloudera Management Console has the following message: "Cloudera Manager reported health … …hostname1: [This host is in maintenance mode.], hostname2: [This host is in maintenance mode.]"
- The cluster moves to ‘Node Failure’ state, and autoscaling is disabled. This typically indicates that some nodes are in the ‘STARTED’ state on the cloud-provider, but they are in ‘Maintenance Mode’ in Cloudera Manager. To remediate this, find the affected nodes in Cloudera Manager, and perform the steps in Scaleup: Commission Services via Cloudera Manager above. Wait for a few minutes for the Cloudera Management Console to sync state. After this, the cluster should move to the running state, and autoscale is re-enabled. Alternately, you can stop the specific nodes on the cloud provider.
- Not enough nodes available - i.e. Autoscale configured with maxNodes, but the instance group has fewer than maxNodes available
- Autoscaling will commission as many nodes as are available, and log an error in the Cloudera Management Console indicating that not enough nodes are available. Once all nodes are started, it will continue to try, causing a loop in which 0 nodes are added in each upscale attempt. To remedy this, when the cluster has all nodes in the RUNNING state, disable autoscaling and perform a scale-up of the host group to reach the ‘maxNodes’ configured for autoscaling (). Re-enable autoscaling.