Specifying a custom Python interpreter
Cloudera Data Visualization includes an embedded Python interpreter by default. However, you can configure the system to use the OS-provided Python or a custom Python build instead. This provides greater flexibility and can improve performance when compatible Python versions are available on your system.
-
To use a non-embedded Python interpreter:
-
Set the following environment variable in the Dataviz Service
Environment Advanced Configuration Snippet (Safety Valve) configuration
to disable the embedded Python.
DATAVIZ_USE_EMBEDDED_PYTHON=false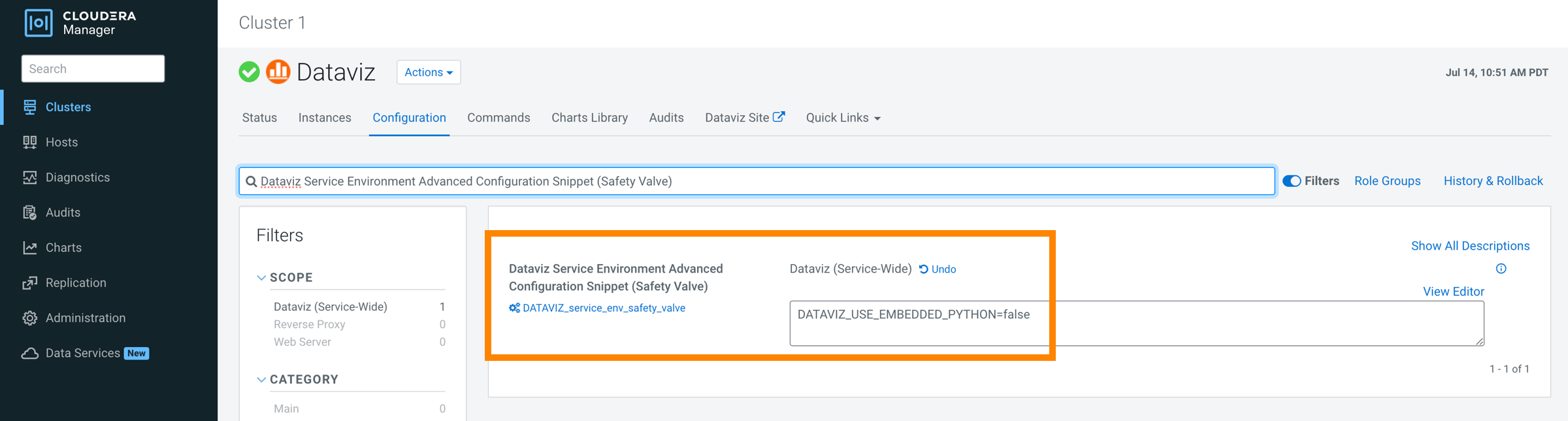
This enables Cloudera Data Visualization to use the system’s default, OS-provided Python interpreter.
-
Set the following environment variable in the Dataviz Service
Environment Advanced Configuration Snippet (Safety Valve) configuration
to disable the embedded Python.