Hive auto-scaling on private clouds
This topic describes how auto-scaling works for Hive Virtual Warehouses in Cloudera Data Warehouse (CDW) Private Cloud.
Auto-scaling for Hive Virtual Warehouses in CDW Private Cloud service is managed by the following components:
- HiveServer: Receives all incoming queries and generates a preliminary query plan that does not include distributing the query across executor nodes. Then it looks for an available query coordinator to send the plan to for distribution to executor nodes.
- Query coordinators: Receives the serialized plan from HiveServer and generates the final query plan that distributes the query tasks across executor nodes for execution. There are as many query coordinators as executor nodes, but there is not a one-to-one correspondence. Instead, each query coordinator interacts only with the executor nodes in a group. For example, if you create a Virtual Warehouse that has 10 nodes (SMALL-size) and you scale up to 30 nodes by 10-node increments, a single query coordinator can only utilize the 10 executors from one group. They can never interact with executors from other groups. This supports effective isolation. Also it is important to note that one query coordinator can only orchestrate the execution of tasks for one query at a time, so the number of query coordinators determines your query parallelism limit.
- Query executor containers: Can run multiple tasks of one or multiple different
queries. Query executor nodes determine the throughput of your system. They are the
executors which are the unit of sizing for Virtual Warehouses:
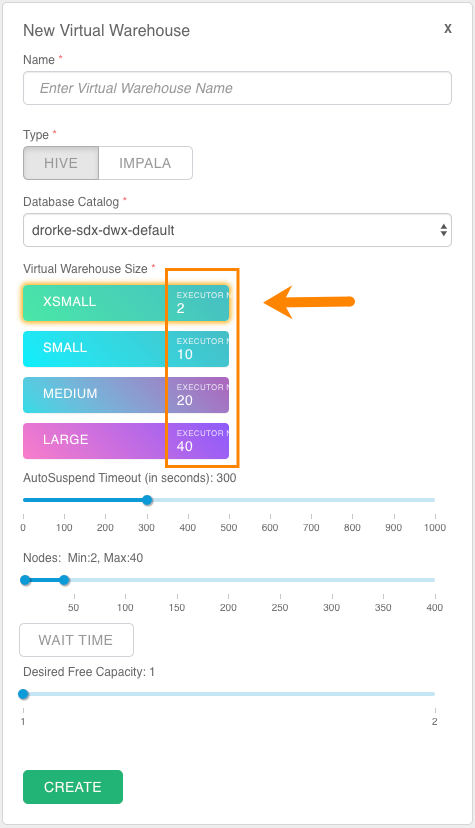
- Executor groups: A group of executors that can run queries. The size of executor group is determined by the size you choose when you first create the Virtual Warehouse (XSMALL, SMALL, MEDIUM, or LARGE). The Virtual Warehouse size determines the maximum number of queries that each executor group can run concurrently. For example, if you create a SMALL Virtual Warehouse, each executor group can handle 10 parallel queries or tasks of up to 10 queries. A single query is always contained within a single executor group and never spans multiple executor groups. The throughput for an individual query is determined by the original size of the warehouse.
Auto-scaling process
Hive Virtual Warehouse auto-scaling manages resources based on query load:

- When users connect to Hive Virtual Warehouses using SQL applications such as Hue, Data Analytics Studio (DAS), or other SQL clients that use JDBC or ODBC, the query is handled by HiveServer. First HiveServer generates a logical plan that does not include distributing the query tasks across executor nodes.
- Then HiveServer locates an available query coordinator in the Virtual Warehouse to handle the query. The query coordinator generates the physical query plan that distributes the query tasks across executor nodes for execution and locates available query executors to handle each query task. Each query coordinator can send query tasks to all query executors in the executor group and tries to optimize for cache locality.
-
Depending on whether WAIT TIME has been set to manage auto-scaling, additional query executor groups are added when the auto-scaling threshold has been exceeded.
WAIT TIME sets how long queries wait in the queue to run. A query is queued if it arrives on HiveServer and no coordinator is available. For example, if WaitTime Seconds is set to 10, queries are waiting to run in the queue for 10 seconds, the warehouse auto-scales up and an additional executor group is deployed until the maximum setting for Nodes:Min:, Max: has been reached. This ensures that your Virtual Warehouse does not take resources away from other workloads.
When no queries are being sent to an executor group, it scales down and the nodes are released. When all executor groups are scaled back to the original executor group created when the warehouse was created and its coordinators and executors are idle, the Virtual Warehouse is suspended according to the value set for AutoSuspend Timeout.
AutoSuspend Timeout
You set the AutoSuspend Timeout when you create a Virtual Warehouse:
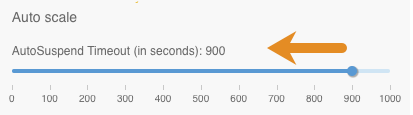
This sets the maximum time that the original warehouse executor group idles after all other executor groups have scaled down and released their resources. The JDBC endpoint is kept up and alive to keep the application connectivity and even respond to queries from the result cache or statistics where possible. AutoSuspend Timeout is independent of the auto-scaling process and only applies to the original executor group and not to any additional executor groups that are created as a result of auto-scaling.
If a query is sent to a suspended Virtual Warehouse and if it cannot be answered from query result cache or statistics, then the query coordinator queues the query. When a queued query is detected, an executor group is immediately added that can run the query on the Virtual Warehouse.