Uploading additional JARs to CDW
You add additional Java Archive (JAR) files to the Cloudera Data Warehouse (CDW) Hive classpath that might be required to support dependency JARs, third-party Serde, or any Hive extensions.
- The JARs are added to the end of the Hive classpath and do not override the Hive JARs.
- Cloudera recommends that you do not use this procedure to add User-Defined Function (UDF) JARs. If you do, then you must restart HiveServer2 or reload the UDF. For more information about reloading functions, see the Hive Data Definition Language (DDL) manual.
-
Log in to the CDW service and from the Overview page,
locate the Hive Virtual Warehouse that uses the bucket or container where you
placed the archive file, and click
 > Edit.
> Edit.
-
Search for
CDW_HIVE_AUX_JARS_PATHand add the archive file to the environment variable.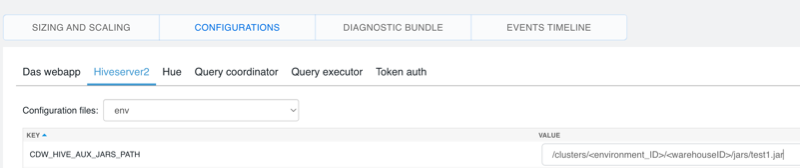
If you add a directory, the .jar or tar.gz files within the directory are copied and extracted. For a tar.gz file, only the JARs present in the top level are copied.Consider the following JAR path - /common-jars/common-jars.tar.gz:/common-jars/single-jar.jar:/serde-specific-jar/serde.jar. In this example,common-jars.tar.gzis extracted andsingle-jar.jarandserde.jarfiles are copied. -
Repeat the previous step and add the archive file or directory for
Query coordinator and Query
executor.
If the
CDW_HIVE_AUX_JARS_PATHenvironment variable is not present, click and add the following custom
configuration:
and add the following custom
configuration:CDW_HIVE_AUX_JARS_PATH=[***VALUE***]