How workload-aware autoscaling works
The Impala planner traverses successively larger executor groups iteratively to find one to run the query efficiently. Traversal stops when the planner finds an acceptable executor group set. In Workload Aware Auto-Scaling, this process is called replanning.
The replan is based on memory and CPU estimates. If the query will not fit into the estimated memory, or if the query needs more cores to run efficiently, the planner looks for an executor group set with sufficient memory. If none is found, the query is queued to the next pool.
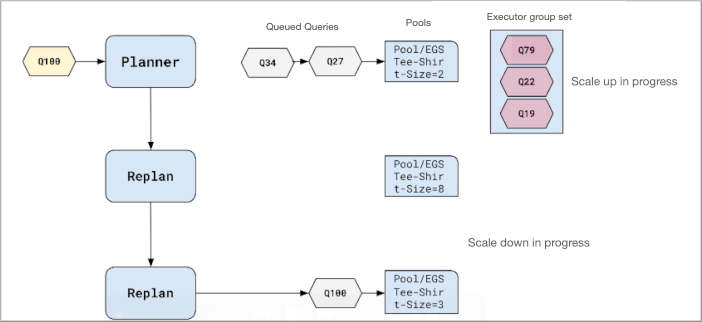
The query enters the panner and generates the conventional query plan. If the resources aren’t available for the query, another replan occurs. The process continues iteratively, and if all executor groups sets fail to meet the criteria for running the query, Workload Aware Auto-Scaling assigns the last group to try to run the query.
After replanning and establishing an executor group set able to run the query, the query enters the admission queue for a pool. The query will get admitted when the resources are available in the pool. The query may or may not succeed, depending on the resource settings and size of the executor group.