Identifying the spill location for Impala temporary data
Impala writes temporary data to S3 to prevent a memory overflow. The result is successful completion of a query instead of an out-of-memory error. When you create an Impala Virtual Warehouse, a path to write temporary data to the Data Lake S3 bucket is configured automatically. You need to know the name of the bucket and then allow Impala to access it.
The Impala Virtual Warehouse attempts to write temporary data to the local Non-Volatile Memory Express (NVMe) SSD on compute instances before spilling to Data Lake S3 bucket. The attempt succeeds only if you configure Impala access to the default scratch location on DataLake S3 bucket.
- Obtain the DWAdmin role.
- Your Impala Virtual Warehouse spill-to-Data-Lake-bucket was configured automatically when you created a new Virtual Warehouse; you are not using an existing Virtual Warehouse that required a manual spill-to-S3 configuration.
-
Go to the Impala Virtual Warehouse >
 > Details.
> Details.
-
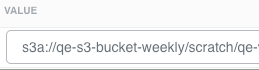
Note the value of the
scratch_dirsproperty.The first path segment of the value is the default scratch location in the Data Lake bucket. For example, qe-s3-bucket-weekly is the S3 bucket name of the default scratch location.