To make sure that your Apache NiFi data flow can be deployed as a function in Cloudera Data Flow, follow the best practices outlined in this
section.
Create a Process Group and associate a Parameter Context to it.
The Parameter Context can itself inherit or not, from other Parameter Contexts. Make
sure that the name of your Parameter Contexts starts with a letter and it only consists of
letters, numbers, and the underscore (_) character.
Go into the Process Group and add an Input Port.
This is the start of your flow where the Cloudera Data Flow Functions
code will “generate” a FlowFile containing the payload generated by the function’s
trigger. See the corresponding sections of each cloud provider in the Cloudera Data Flow Functions documentation to see what the FlowFile’s
content would be.
Add your processors to extract the required data from the FlowFile and perform the
required actions.
Once the flow is designed, parameterize all processor and controller service properties
that should be externalized for configuration during function creation.
Make sure that all parameters have names that start with a letter and only consist of
letters, numbers, and the underscore (_) character.
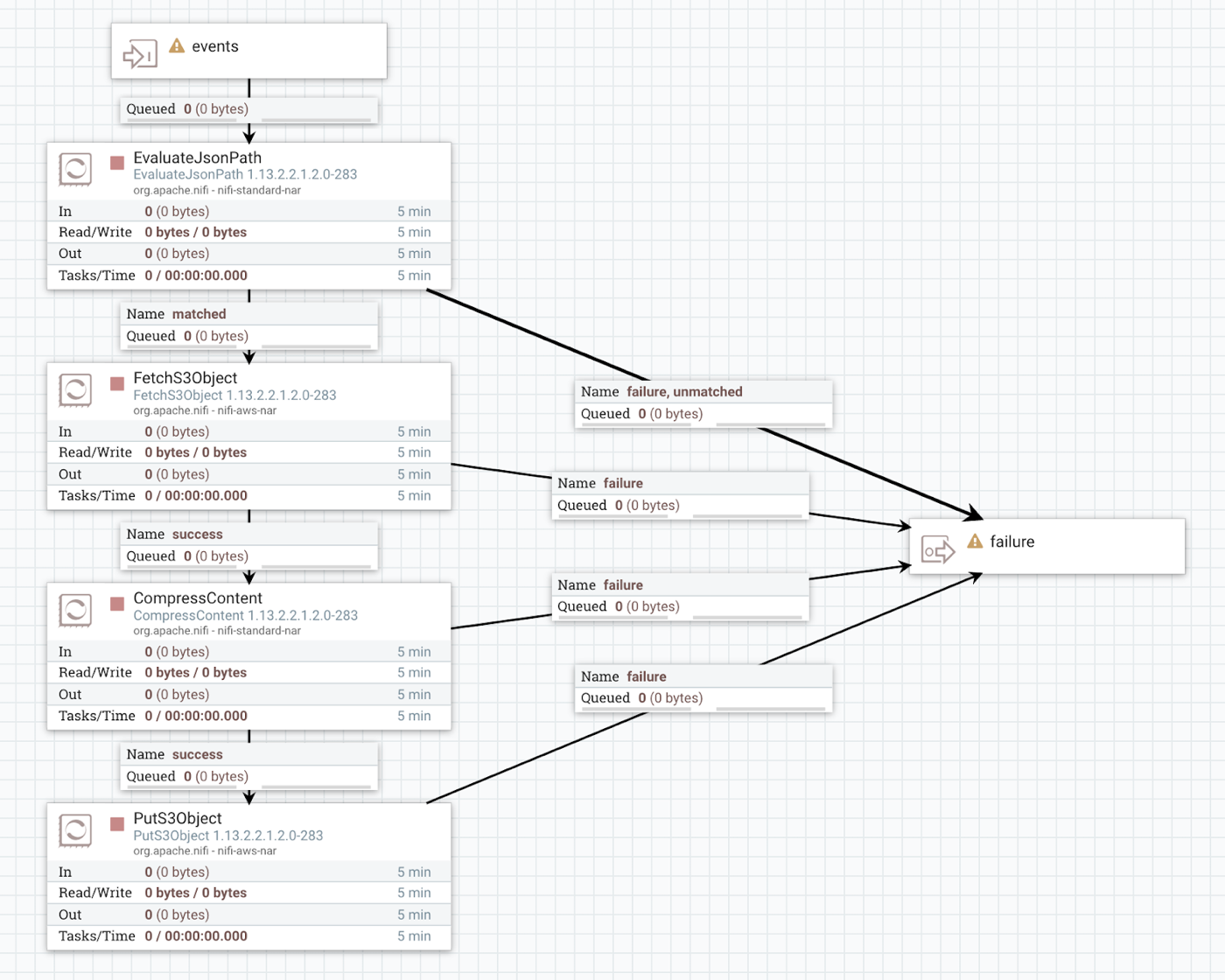
S3 trigger
In this example, use the EvaluateJsonPath processor to extract the bucket name and the
object key, and continue the flow as you wish, for example fetch the data, compress it and
send the result to a different location.
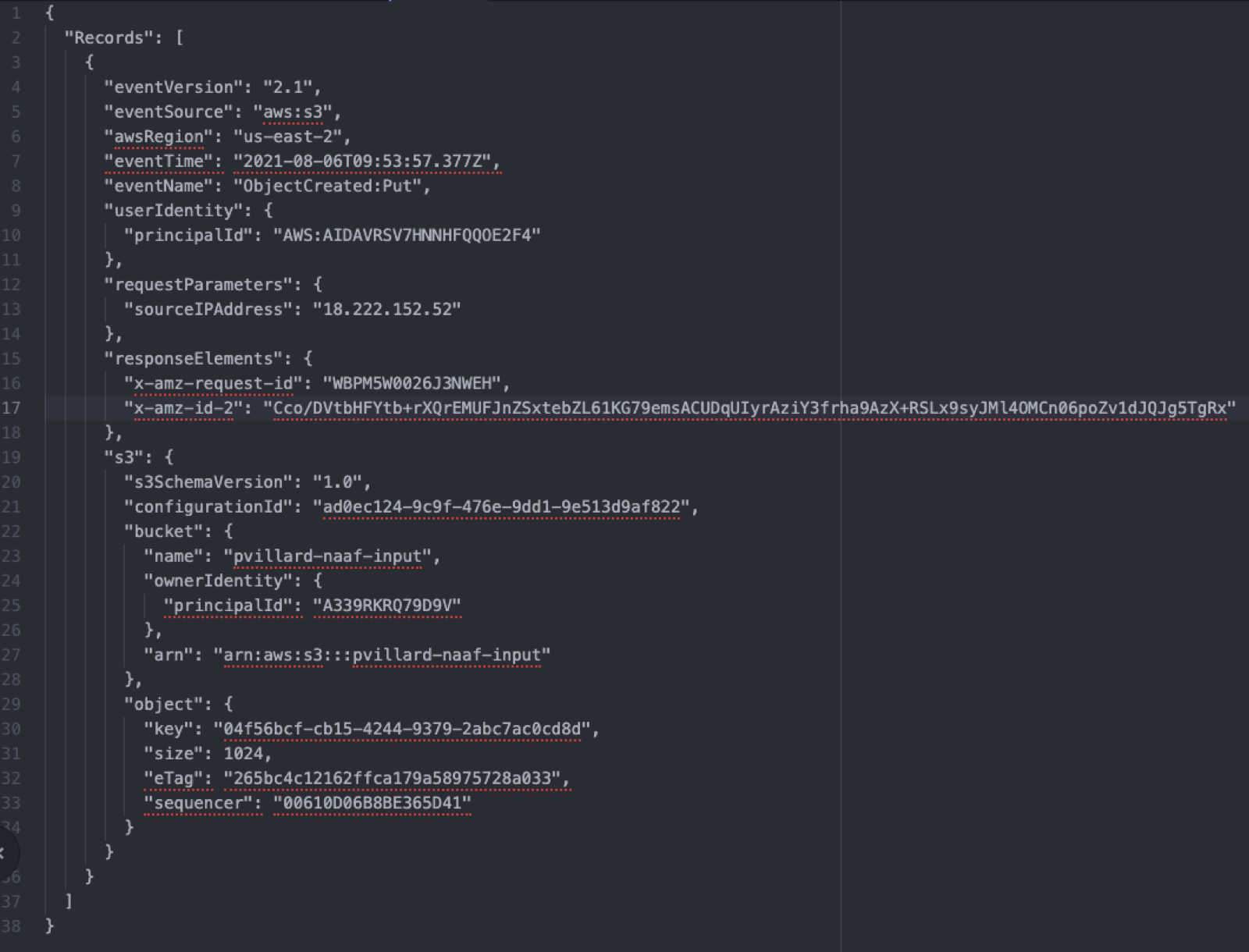
When using an AWS Lambda with an S3 trigger, the generated FlowFile would have a payload
similar to this:
Getting the payload associated with a trigger
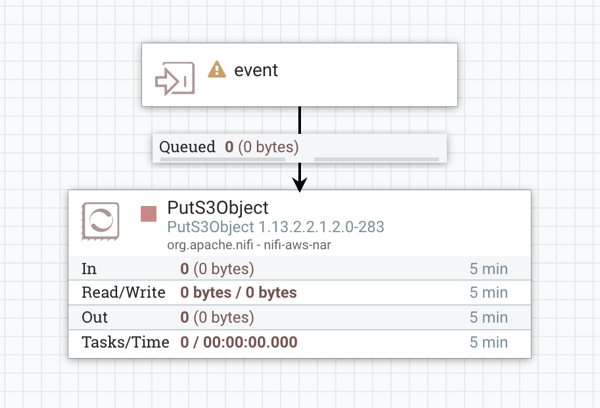
You can design a flow that would just push as-is the event generated by
the function’s trigger into S3. This can be useful when you do not know beforehand what
would be generated by a given trigger.