Access on-premise datasets in place without replication
Learn about the advantages of storing data on-premises and processing in the public cloud.
In this hybrid model, data is physically stored in the on-premise infrastructure, for example, HDFS or Ozone, while processing takes place in the public cloud, for example, using Apache Spark, Hive, or Impala. Although compute runs in the cloud, the data source remains on premises. Workloads submitted to the cloud directly access on-premise data. The workload execution plan dictates the strict data subsets that are leveraged in cloud for processing without creating data copies.
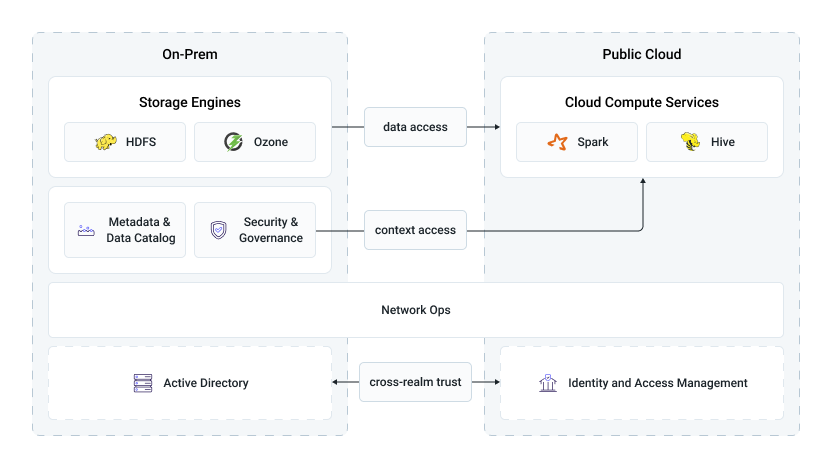
The primary advantage of this model is that analytics applications typically do not need to be rewritten, as logical paths and data structures remain the same. This avoids the cost and complexity of application redesign or full data migration. It is especially efficient for handling burst workloads where temporarily increased compute capacity is required.
Another benefit is keeping metadata and security management centralized on premises. This means table definitions, access permissions, audit policies, and governance rules are enforced consistently, regardless of whether the query runs in the cloud or on premises.