Using Hybrid Data Hubs to burst Cloudera on premises workloads
Learn how to burst Cloudera on premises to Cloudera Hybrid Data Hubs.
Hybrid Data Hubs extend on-premise capabilities by providing autoscaling cloud compute resources. Workloads submitted to cloud-based engines, such as Spark and Hive, access on-premises datasets in-place, strictly adhering to existing local security policies.
Because Hybrid Data Hubs maintain runtime parity with the on-premise cluster, workloads do not require reengineering to migrate between platforms. Consequently, on-premise workloads can be burst to the cloud simply by submitting them to the corresponding engine within the Hybrid Data Hub.
The following diagram represents the lifecycle of such a Spark workload:
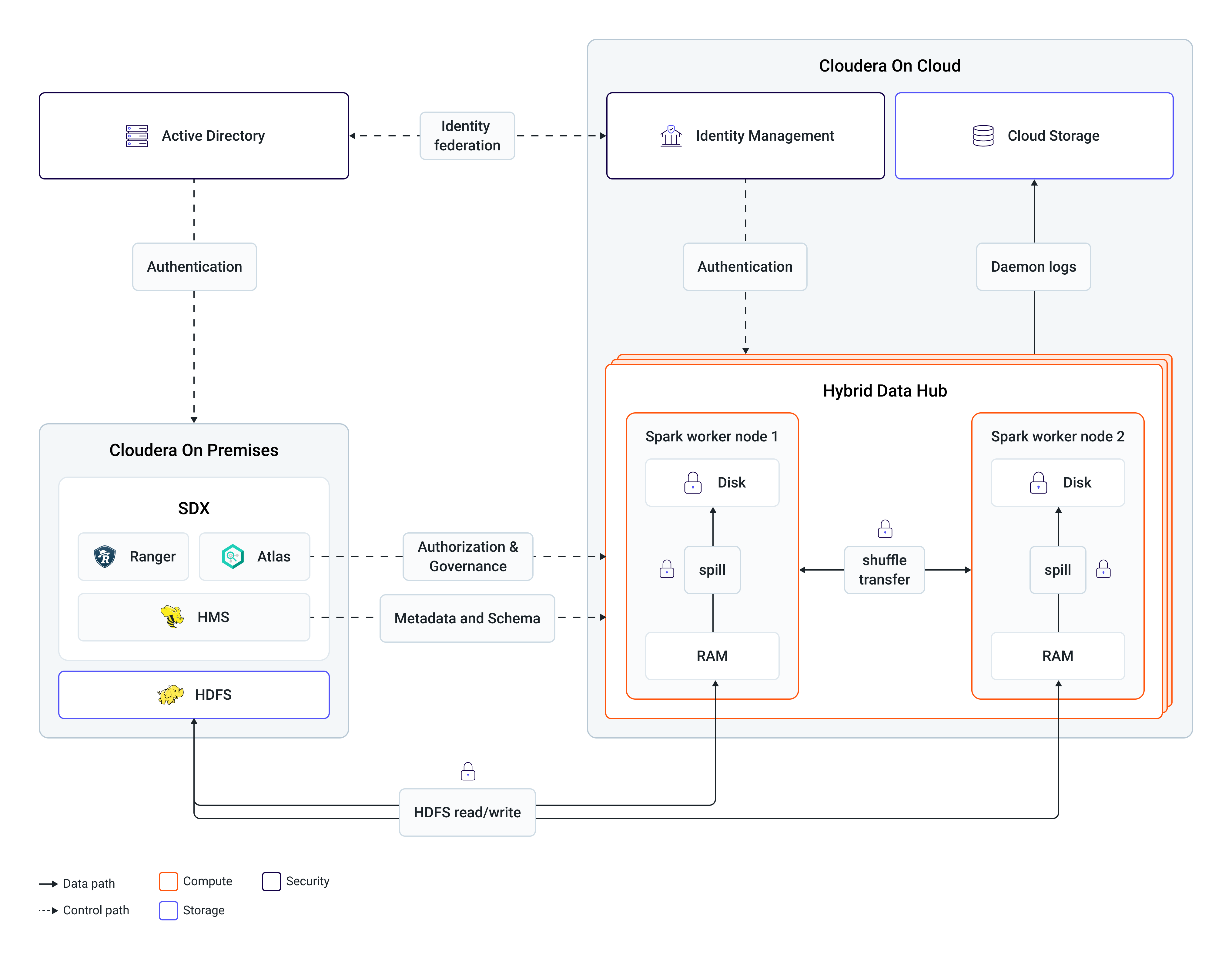
When the on-premises Spark workload is submitted to Hybrid Data Hub, its Spark engine generates an execution plan that reads only the necessary data subsets, such as specific partitions or columns, from the on-premise HDFS.
Job processing occurs within the cloud infrastructure and the final results are written back to the on-premise storage if a persist stage exists. All intermediate data generated during execution is ephemeral and is cleaned up at job completion.
Additionally, on-premise workload schedules can be optimized for compute redundancy. By integrating Hybrid Data Hub endpoints, such as Spark and Hive, into the scheduler logic, jobs can be automatically submitted to the hybrid environment whenever on-premise YARN utilization approaches capacity.