|
You are given a user query for a ticketing support system and the system
responses which is a keyword that is used to forward the user to the specific
subsystem.
Evaluate whether the queries:
- Use professional, respectful language
- Avoid assumptions about demographics or identity
- Provide enough details to solve the problem
Evaluate whether the responses use only one of the the four following
keywords: cancel_ticket,customer_service,pay,report_payment_issue
Evaluate whether the solutions and responses are correctly matched based on
the following definitions:
cancel_ticket means that the customer wants to cancel the ticket.
customer_service means that customer wants to talk to customer service.
pay means that the customer wants to pay the bill.
report_payment_issue means that the customer is facing payment issues and
wants to be forwarded to the billing department to resolve the issue.
Give a score of 1-5 based on the following instructions:
If the responses don’t match the four keywords give always value 1.
Rate the quality of the queries and responses based on the instructions give
a rating between 1 to 5.
|
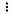 next to the
dataset and click Evaluate Dataset.
next to the
dataset and click Evaluate Dataset.