Set up a data connection for CDP One
In CDP One, you can set up a data connection to the DataHub cluster. You can set up a connection using the New Connection dialog, or by using raw code inside your project. Both approaches are shown below.
-
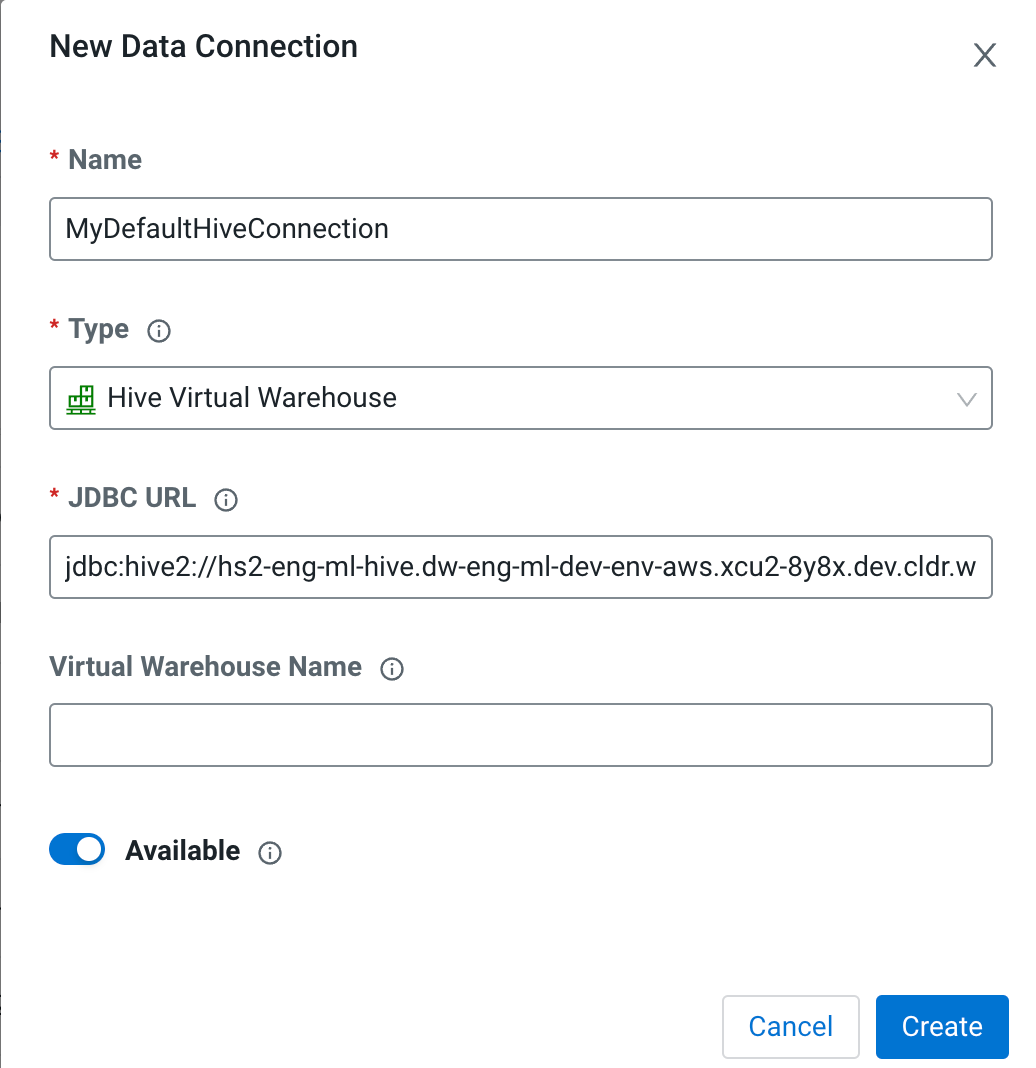
(Optional) Enter the Virtual Warehouse Name. This is the
name of the warehouse in Cloudera Data Warehouse.
Set up a CDP One data connection using raw code
It is recommended to use the New Connection dialog to create a new data connection. If needed, you can also set up a data connection in your project code by using and adapting the following code snippet.
from impala.dbapi import connect
#Example connection string:
# jdbc:hive2://my-test-master0.eng-ml-i.svbr-nqvp.int.cldr.work/;ssl=true;transportMode=http;httpPath=my-test/cdp-proxy-api/hive
conn = connect(
host = "my-test-master0.eng-ml-i.svbr-nqvp.int.cldr.work",
port = 443,
auth_mechanism = "LDAP",
use_ssl = True,
use_http_transport = True,
http_path = "my-test/cdp-proxy-api/hive",
user = "csso_me",
password = "Test@123")
cursor = conn.cursor()
cursor.execute("select * from 3yearpop")
for row in cursor:
print(row)
cursor.close()
conn.close()