Troubleshooting an abnormal job duration
You can identify areas of risk from jobs running on your workload cluster that complete within an unusual time period, using Cloudera Observability.
Steps with examples from a Virtual Cluster's Spark engine are used to explain how to further investigate and troubleshoot the cause of an abnormal job duration.
-
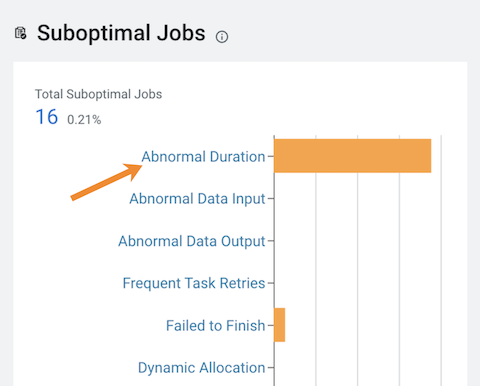
Scroll down to the Suboptimal Jobs chart widget and
click the Abnormal Duration health check bar.
The Jobs page opens, listing all the jobs that triggered the Abnormal Duration Health check during the time period, including their health status, the length of time the job took to run, the user who ran the job, the job identification number, and the amount of CPU used to run the job.
-
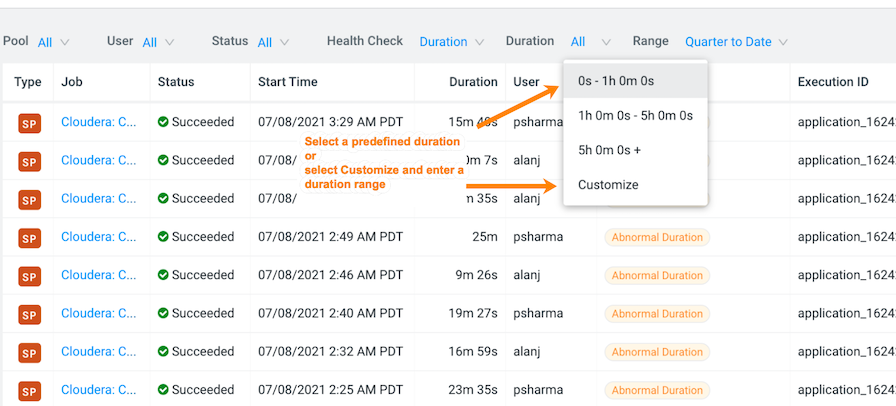
Specify a specific amount of time in which the job either ran less than or more
than the Health check rule by either selecting a predefined time duration or
selecting Customize and enter the minimum or maximum time
period from the Duration filter.
-
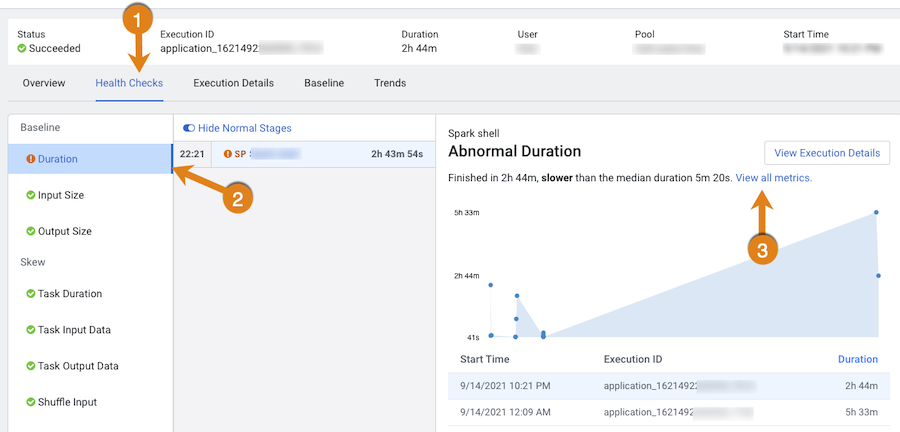
Display more information about the job's duration by selecting
Duration from the Baseline
section. As shown in the image below.
In the following example, the job finished much slower than the baseline duration, which is the aggregate calculated over multiple jobs.
-
Continue to analyze and search for probable causes by doing one or more of the
following:
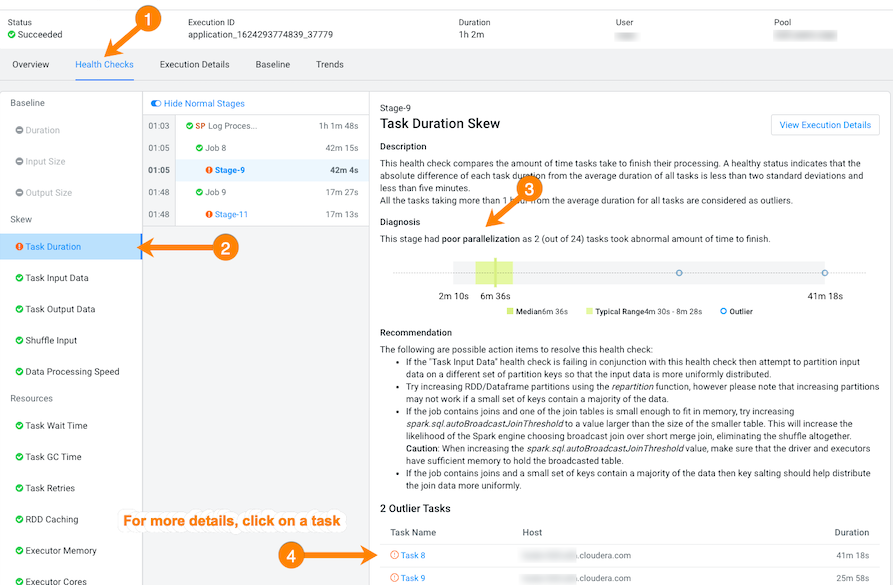
- To display more information about the length of time the processing
tasks took within a job, select Task Duration, which
opens a panel that describes the health check, displays information about
the possible causes, and lists recommended solutions. In the following example, issues arose during Stage-9 of the job due to poor parallelization. The Recommendation section lists items for you to complete that may resolve the problem and the specific outlier tasks that produced the unusual results:
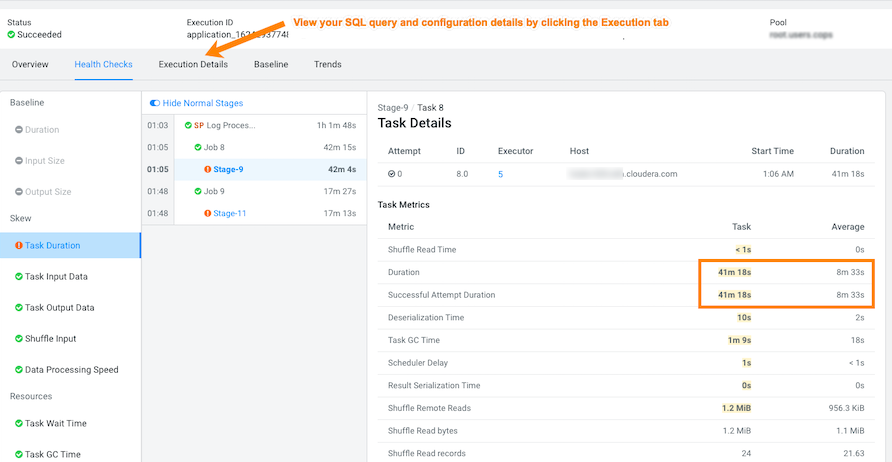
- To display more details about an outlier, click the outlier task, which
opens the Task Details panel. In the following example, the Task Details show that the outlier task took significantly more time to complete compared to previous runs. In this case, 41 minutes as compared to 8 minutes:
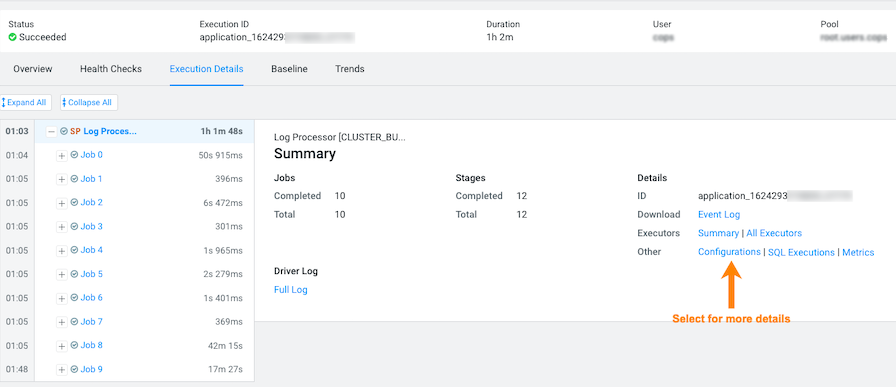
- To gain more insights about the task's duration, such as checking memory
allocation, click the Execution Details tab and then
in the Summary panel, click Configurations:
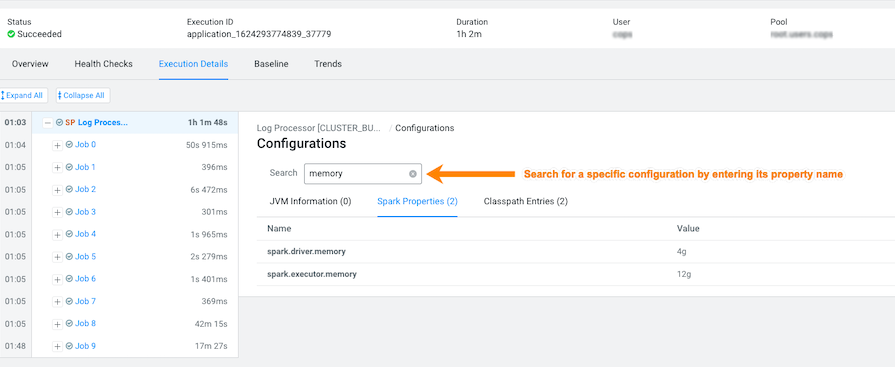
- In the Configurations panel, click the Spark
Properties tab and search for the memory configuration
settings and their values. If memory is less than the recommended value,
increasing its value will improve cluster performance:
- To display more information about the length of time the processing
tasks took within a job, select Task Duration, which
opens a panel that describes the health check, displays information about
the possible causes, and lists recommended solutions.