Hive Warehouse Connector for accessing Apache Spark data
The Hive Warehouse Connector (HWC) is a Spark library/plugin that is launched with the Spark app. You can use the Hive Warehouse Connector API to access any managed Hive table from Spark. Apache Ranger and the HiveWarehouseConnector library provide row and column, fine-grained access to the data.
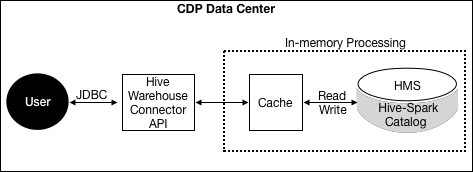
In CDP Public Cloud and CDP Data Center, Spark and Hive share a catalog in the Hive metastore (HMS).
CDP Public Cloud Processing
In CDP Public Cloud, to read ACID, or other Hive-managed tables, from Spark using low-latency analytical processing (LLAP) is recommended.
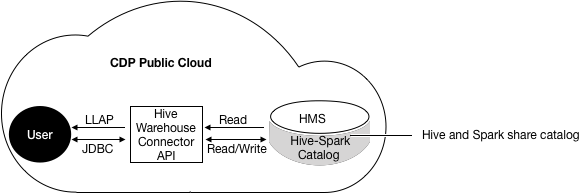
To write to ACID, or other managed tables, from Spark you must use JDBC. HWC is not required to access external tables from Spark. Spark can directly access Hive external tables using spark sql instead of HWC. However, HWC also supports reading external tables.
Using the HWC, you can read and write Apache Spark DataFrames and Streaming DataFrames.
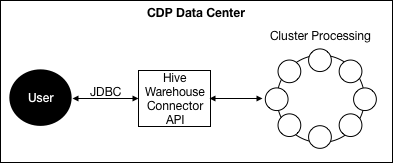
CDP Data Center Processing
HWC Limitations
- HWC supports reading tables in any format, but currently supports writing tables in ORC format only.
- Table stats (basic stats and column stats )are not generated when you write a DataFrame to Hive.
- The spark thrift server is not supported.
- The Hive Union data type is not supported.
- Transaction semantics of Spark RDDs are not ensured when using Spark Direct Reader to read ACID tables.
- When the HWC API save mode is overwrite, writes are limited.
You cannot read from and overwrite the same table. If your query accesses only one table and you try to overwrite that table using an HWC API write method, a deadlock state might occur. Do not attempt this operation.
Example: Operation Not Supported
scala> val df = hive.executeQuery("select * from t1") scala> df.write.format("com.hortonworks.spark.sql.hive.llap.HiveWarehouseConnector").mode("overwrite").option("table", "t1").save
Supported applications and operations
- Spark shell
- PySpark
- The spark-submit script
- Describing a table
- Creating a table in ORC using .createTable() or in any format using .executeUpdate()
- Writing to a table in ORC format
- Selecting Hive data and retrieving a DataFrame
- Writing a DataFrame to a Hive-managed ORC table in batch
- Executing a Hive update statement
- Reading table data, transforming it in Spark, and writing it to a new Hive table
- Writing a DataFrame or Spark stream to Hive using HiveStreaming
- Partitioning data when writing a DataFrame