
Configuring HWC in CDP Public Cloud
You use the Hive Warehouse Connector (HWC) either transparently through spark sql or by using HWC API commands. You configure HWC processing to use LLAP or not, based on your use case.
To read ACID, or other Hive-managed tables, from Spark using low-latency analytical processing (LLAP) is recommended.
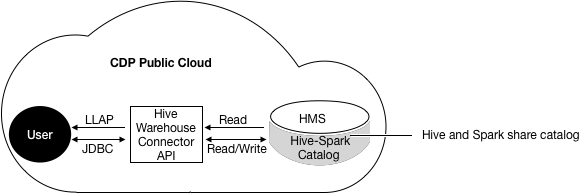
Low-latency analytical processing (LLAP) is recommended for reading ACID, or other Hive-managed tables, from Spark. You do not need LLAP to write to ACID, or other managed tables, from Spark. You do not need LLAP to access external tables from Spark.
Configuring the HWC mode for reads
The HWC runs in the following modes for reading Hive-managed tables:
- LLAP
- true
- false
- JDBC
- cluster
- client
configuration/spark-defaults.conf. Alternatively, you can set the
properties using the spark-submit/spark-shell --conf option. spark.datasource.hive.warehouse.read.via.llapConfigures LLAP mode on or off. Values: true or false
spark.datasource.hive.warehouse.read.jdbc.modeConfigures JDBC mode. Values: cluster or client
spark.sql.hive.hiveserver2.jdbc.urlThe Hive JDBC url in /etc/hive/conf/beeline-site.xml.
spark.datasource.hive.warehouse.metastoreUriURI of Hive metastore. In Cloudera Manager, click , search for
hive.metastore.uris, and use that value.spark.datasource.hive.warehouse.load.staging.dirTemporary staging location required by HWC.
Set the value to a file system location where the HWC user has write permission.
| Tasks | Use HWC | Recommended HWC Mode |
|---|---|---|
| Read Hive managed tables from Spark | Yes | LLAP mode=true |
| Write Hive managed tables from Spark | Yes | N/A |
| Read Hive external tables from Spark | Ok, but unnecessary | N/A |
| Write Hive external tables from Spark | Ok, but unnecessary | N/A |
